 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence Analysis of Decentralized ASGD
Sep 07, 2023

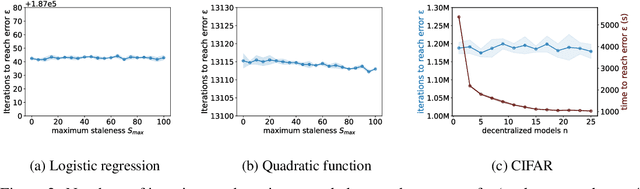
Over the last decades, Stochastic Gradient Descent (SGD) has been intensively studied by the Machine Learning community. Despite its versatility and excellent performance, the optimization of large models via SGD still is a time-consuming task. To reduce training time, it is common to distribute the training process across multiple devices. Recently, it has been shown that the convergence of asynchronous SGD (ASGD) will always be faster than mini-batch SGD. However, despite these improvements in the theoretical bounds, most ASGD convergence-rate proofs still rely on a centralized parameter server, which is prone to become a bottleneck when scaling out the gradient computations across many distributed processes. In this paper, we present a novel convergence-rate analysis for decentralized and asynchronous SGD (DASGD) which does not require partial synchronization among nodes nor restrictive network topologies. Specifically, we provide a bound of $\mathcal{O}(\sigma\epsilon^{-2}) + \mathcal{O}(QS_{avg}\epsilon^{-3/2}) + \mathcal{O}(S_{avg}\epsilon^{-1})$ for the convergence rate of DASGD, where $S_{avg}$ is the average staleness between models, $Q$ is a constant that bounds the norm of the gradients, and $\epsilon$ is a (small) error that is allowed within the bound. Furthermore, when gradients are not bounded, we prove the convergence rate of DASGD to be $\mathcal{O}(\sigma\epsilon^{-2}) + \mathcal{O}(\sqrt{\hat{S}_{avg}\hat{S}_{max}}\epsilon^{-1})$, with $\hat{S}_{max}$ and $\hat{S}_{avg}$ representing a loose version of the average and maximum staleness, respectively. Our convergence proof holds for a fixed stepsize and any non-convex, homogeneous, and L-smooth objective function. We anticipate that our results will be of high relevance for the adoption of DASGD by a broad community of researchers and developers.