 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe eDiscovery Medicine Show
Sep 28, 2021The practice of bloodletting gradually fell into disfavor as a growing body of scientific evidence showed its ineffectiveness and demonstrated the effectiveness of various pharmaceuticals for the prevention and treatment of certain diseases. At the same time, the patent medicine industry promoted ineffective remedies at medicine shows featuring entertainment, testimonials, and pseudo-scientific claims with all the trappings--but none of the methodology--of science. Today, many producing parties and eDiscovery vendors similarly promote obsolete technology as well as unvetted tools labeled "artificial intelligence" or "technology-assisted review," along with unsound validation protocols. This situation will end only when eDiscovery technologies and tools are subject to testing using the methods of information retrieval.
Impact of Feature Selection on Micro-Text Classification
Aug 27, 2017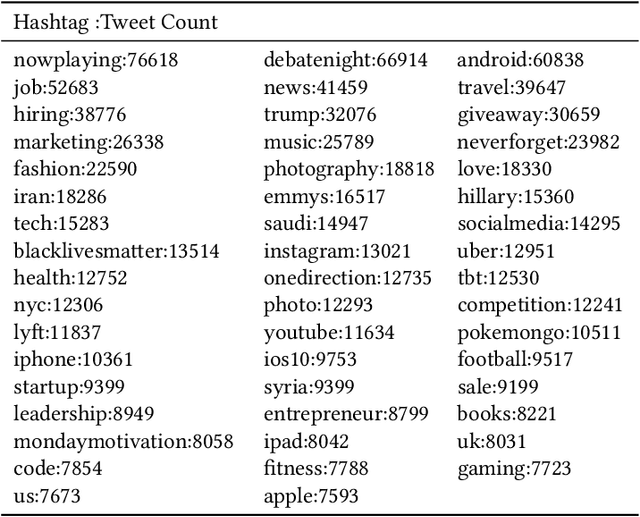
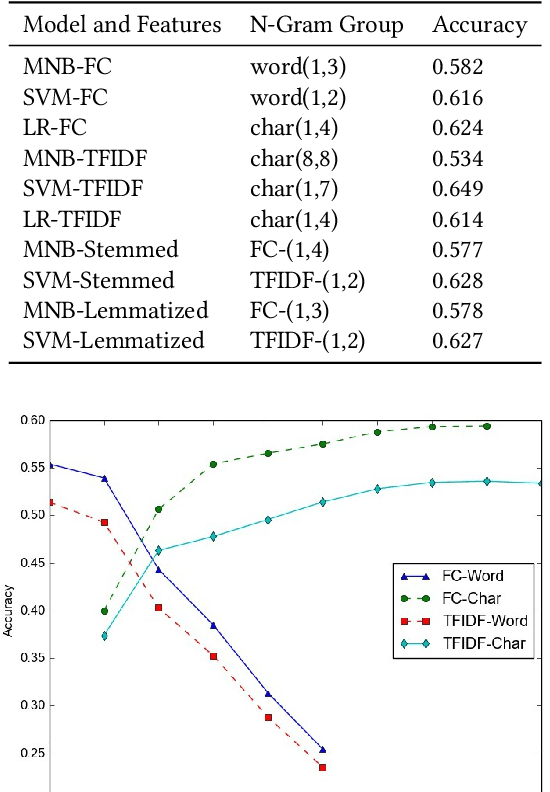
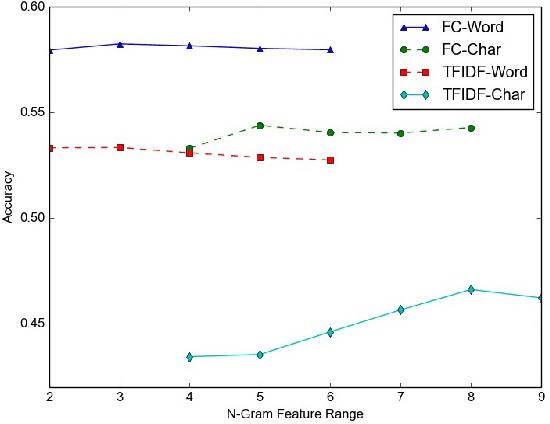
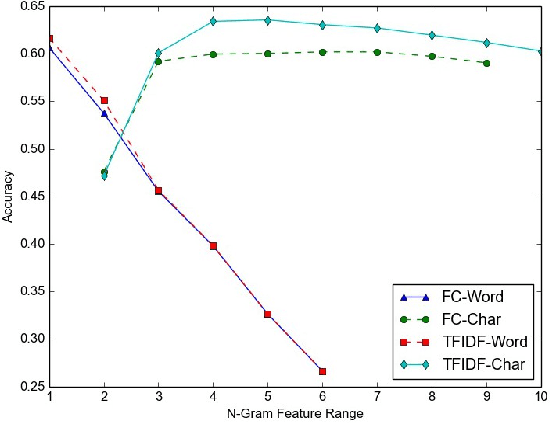
Social media datasets, especially Twitter tweets, are popular in the field of text classification. Tweets are a valuable source of micro-text (sometimes referred to as "micro-blogs"), and have been studied in domains such as sentiment analysis, recommendation systems, spam detection, clustering, among others. Tweets often include keywords referred to as "Hashtags" that can be used as labels for the tweet. Using tweets encompassing 50 labels, we studied the impact of word versus character-level feature selection and extraction on different learners to solve a multi-class classification task. We show that feature extraction of simple character-level groups performs better than simple word groups and pre-processing methods like normalizing using Porter's Stemming and Part-of-Speech ("POS")-Lemmatization.
Autonomy and Reliability of Continuous Active Learning for Technology-Assisted Review
Apr 26, 2015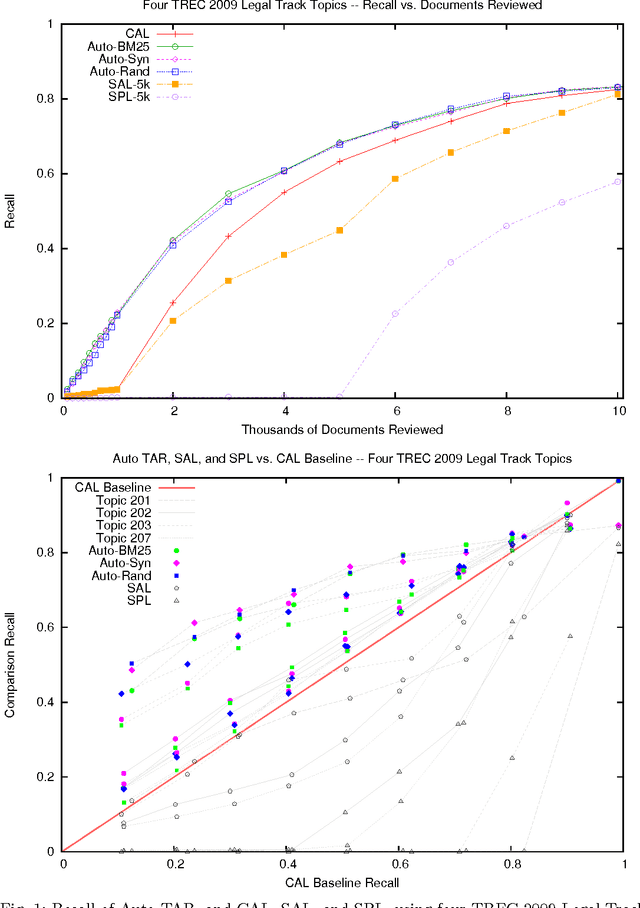
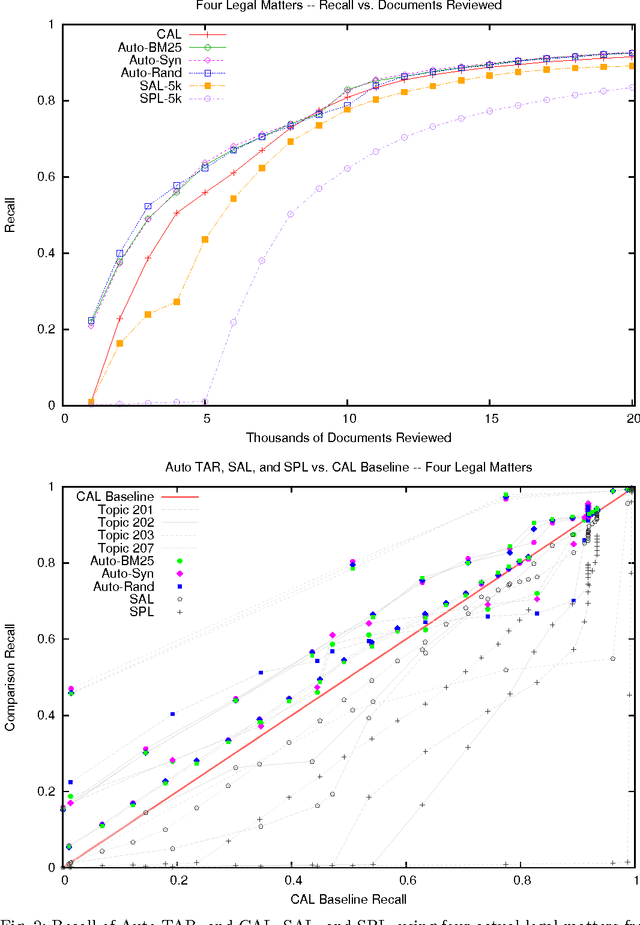
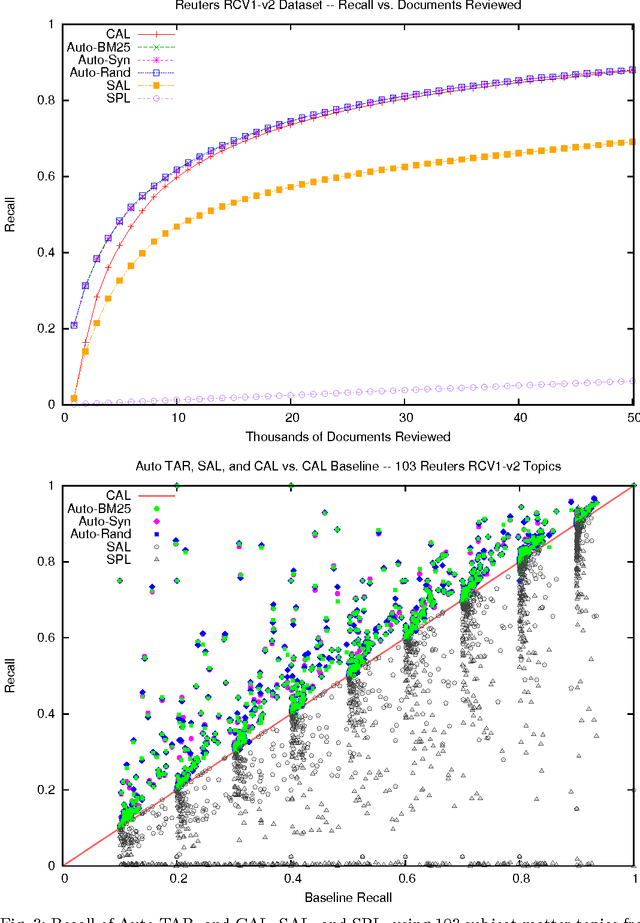
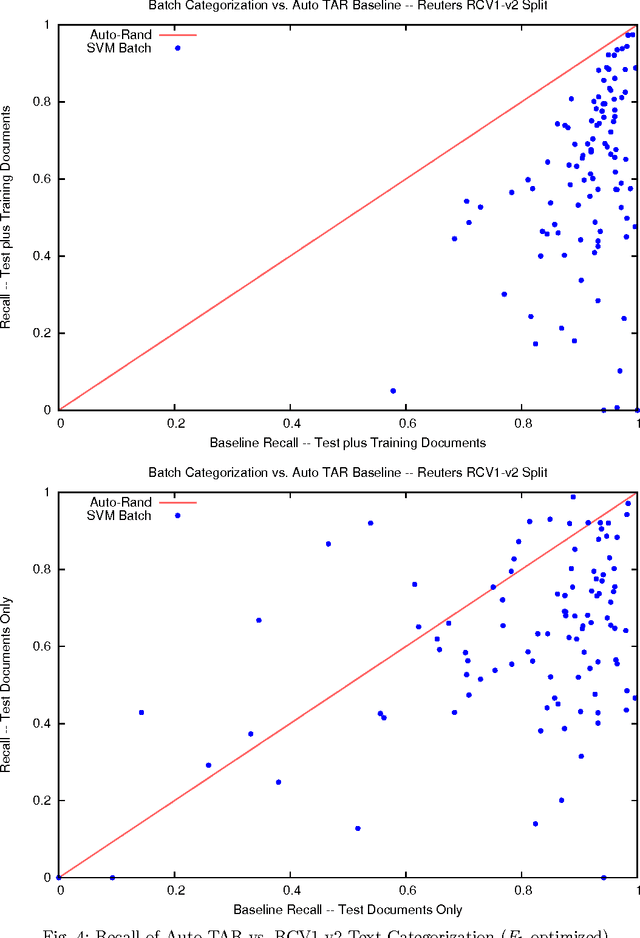
We enhance the autonomy of the continuous active learning method shown by Cormack and Grossman (SIGIR 2014) to be effective for technology-assisted review, in which documents from a collection are retrieved and reviewed, using relevance feedback, until substantially all of the relevant documents have been reviewed. Autonomy is enhanced through the elimination of topic-specific and dataset-specific tuning parameters, so that the sole input required by the user is, at the outset, a short query, topic description, or single relevant document; and, throughout the review, ongoing relevance assessments of the retrieved documents. We show that our enhancements consistently yield superior results to Cormack and Grossman's version of continuous active learning, and other methods, not only on average, but on the vast majority of topics from four separate sets of tasks: the legal datasets examined by Cormack and Grossman, the Reuters RCV1-v2 subject categories, the TREC 6 AdHoc task, and the construction of the TREC 2002 filtering test collection.