 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Is Effort: Estimating Human Post-Editing Time for Grammar Error Correction Tool Evaluation
Oct 05, 2025Text editing can involve several iterations of revision. Incorporating an efficient Grammar Error Correction (GEC) tool in the initial correction round can significantly impact further human editing effort and final text quality. This raises an interesting question to quantify GEC Tool usability: How much effort can the GEC Tool save users? We present the first large-scale dataset of post-editing (PE) time annotations and corrections for two English GEC test datasets (BEA19 and CoNLL14). We introduce Post-Editing Effort in Time (PEET) for GEC Tools as a human-focused evaluation scorer to rank any GEC Tool by estimating PE time-to-correct. Using our dataset, we quantify the amount of time saved by GEC Tools in text editing. Analyzing the edit type indicated that determining whether a sentence needs correction and edits like paraphrasing and punctuation changes had the greatest impact on PE time. Finally, comparison with human rankings shows that PEET correlates well with technical effort judgment, providing a new human-centric direction for evaluating GEC tool usability. We release our dataset and code at: https://github.com/ankitvad/PEET_Scorer.
Impact of Feature Selection on Micro-Text Classification
Aug 27, 2017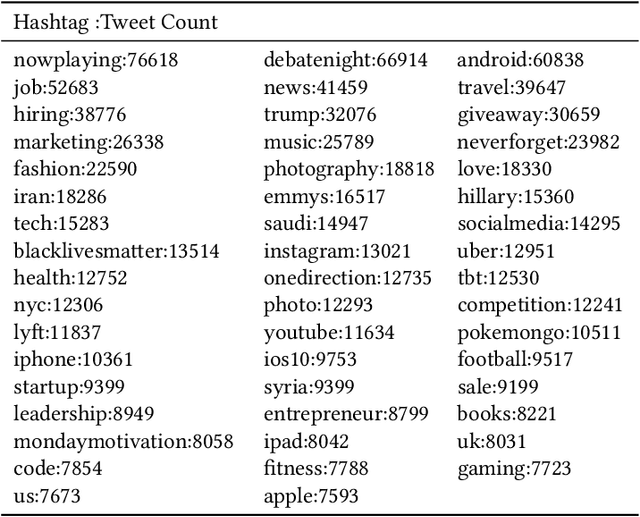
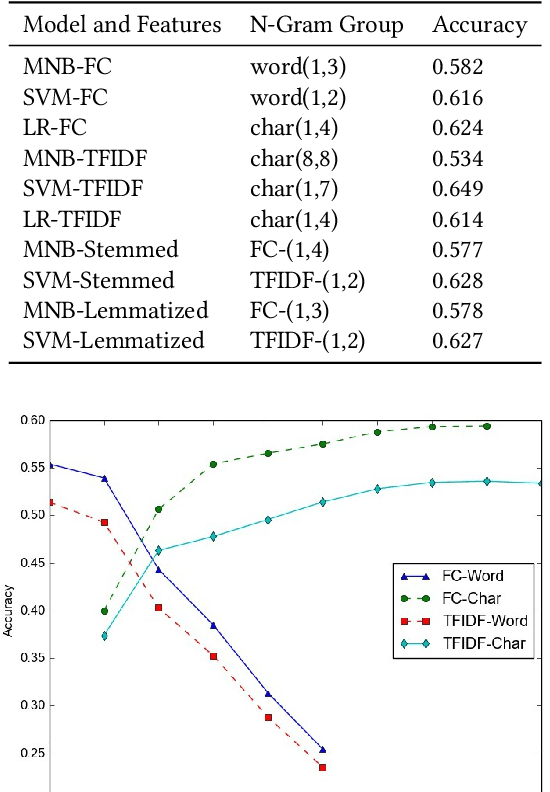
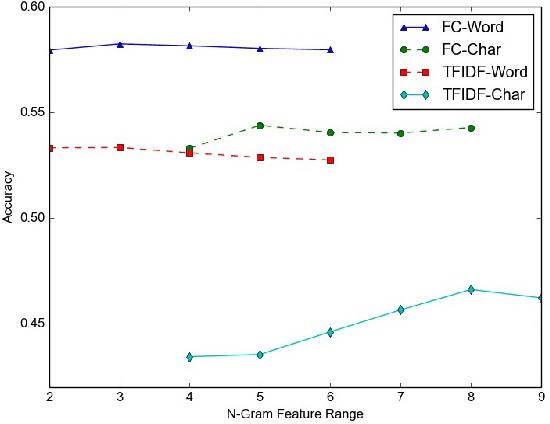
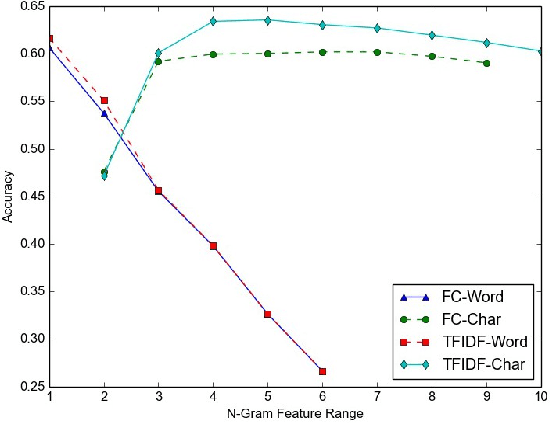
Social media datasets, especially Twitter tweets, are popular in the field of text classification. Tweets are a valuable source of micro-text (sometimes referred to as "micro-blogs"), and have been studied in domains such as sentiment analysis, recommendation systems, spam detection, clustering, among others. Tweets often include keywords referred to as "Hashtags" that can be used as labels for the tweet. Using tweets encompassing 50 labels, we studied the impact of word versus character-level feature selection and extraction on different learners to solve a multi-class classification task. We show that feature extraction of simple character-level groups performs better than simple word groups and pre-processing methods like normalizing using Porter's Stemming and Part-of-Speech ("POS")-Lemmatization.