 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiologically Inspired Oscillating Activation Functions Can Bridge the Performance Gap between Biological and Artificial Neurons
Nov 07, 2021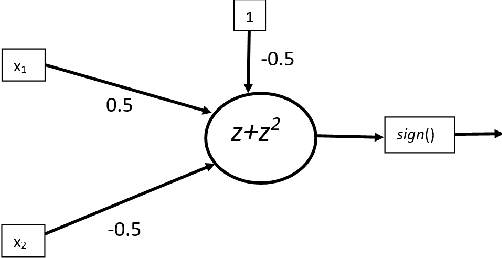
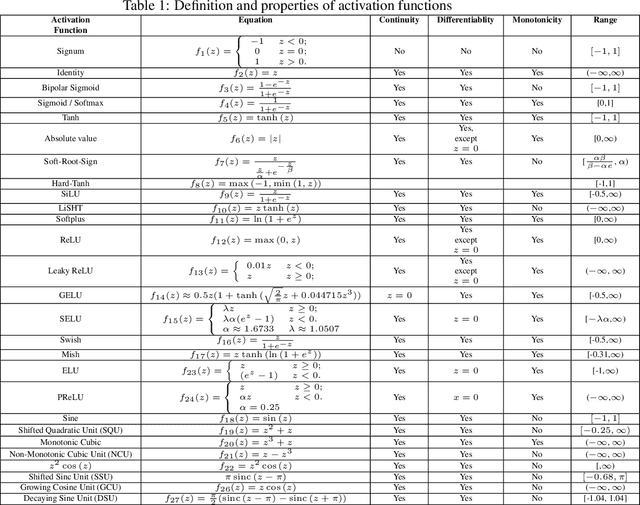
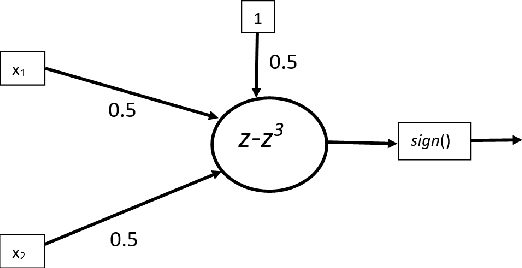
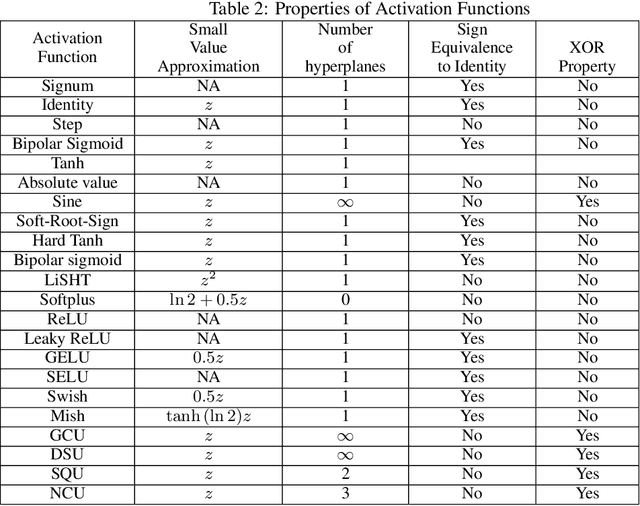
Nonlinear activation functions endow neural networks with the ability to learn complex high-dimensional functions. The choice of activation function is a crucial hyperparameter that determines the performance of deep neural networks. It significantly affects the gradient flow, speed of training and ultimately the representation power of the neural network. Saturating activation functions like sigmoids suffer from the vanishing gradient problem and cannot be used in deep neural networks. Universal approximation theorems guarantee that multilayer networks of sigmoids and ReLU can learn arbitrarily complex continuous functions to any accuracy. Despite the ability of multilayer neural networks to learn arbitrarily complex activation functions, each neuron in a conventional neural network (networks using sigmoids and ReLU like activations) has a single hyperplane as its decision boundary and hence makes a linear classification. Thus single neurons with sigmoidal, ReLU, Swish, and Mish activation functions cannot learn the XOR function. Recent research has discovered biological neurons in layers two and three of the human cortex having oscillating activation functions and capable of individually learning the XOR function. The presence of oscillating activation functions in biological neural neurons might partially explain the performance gap between biological and artificial neural networks. This paper proposes 4 new oscillating activation functions which enable individual neurons to learn the XOR function without manual feature engineering. The paper explores the possibility of using oscillating activation functions to solve classification problems with fewer neurons and reduce training time.