 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mason-Alberta Phonetic Segmenter: A forced alignment system based on deep neural networks and interpolation
Oct 24, 2023



Forced alignment systems automatically determine boundaries between segments in speech data, given an orthographic transcription. These tools are commonplace in phonetics to facilitate the use of speech data that would be infeasible to manually transcribe and segment. In the present paper, we describe a new neural network-based forced alignment system, the Mason-Alberta Phonetic Segmenter (MAPS). The MAPS aligner serves as a testbed for two possible improvements we pursue for forced alignment systems. The first is treating the acoustic model in a forced aligner as a tagging task, rather than a classification task, motivated by the common understanding that segments in speech are not truly discrete and commonly overlap. The second is an interpolation technique to allow boundaries more precise than the common 10 ms limit in modern forced alignment systems. We compare configurations of our system to a state-of-the-art system, the Montreal Forced Aligner. The tagging approach did not generally yield improved results over the Montreal Forced Aligner. However, a system with the interpolation technique had a 27.92% increase relative to the Montreal Forced Aligner in the amount of boundaries within 10 ms of the target on the test set. We also reflect on the task and training process for acoustic modeling in forced alignment, highlighting how the output targets for these models do not match phoneticians' conception of similarity between phones and that reconciliation of this tension may require rethinking the task and output targets or how speech itself should be segmented.
Acoustic absement in detail: Quantifying acoustic differences across time-series representations of speech data
Apr 14, 2023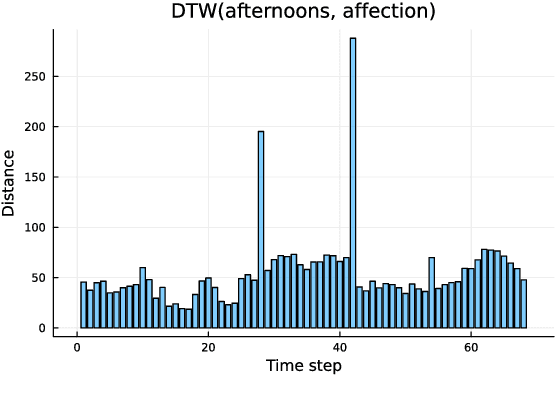
The speech signal is a consummate example of time-series data. The acoustics of the signal change over time, sometimes dramatically. Yet, the most common type of comparison we perform in phonetics is between instantaneous acoustic measurements, such as formant values. In the present paper, I discuss the concept of absement as a quantification of differences between two time-series. I then provide an experimental example of absement applied to phonetic analysis for human and/or computer speech recognition. The experiment is a template-based speech recognition task, using dynamic time warping to compare the acoustics between recordings of isolated words. A recognition accuracy of 57.9% was achieved. The results of the experiment are discussed in terms of using absement as a tool, as well as the implications of using acoustics-only models of spoken word recognition with the word as the smallest discrete linguistic unit.