 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of Deep Learning to the Design of Enhanced Wireless Communication Systems
May 02, 2022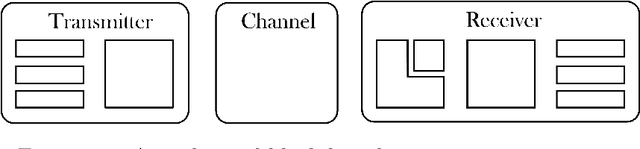
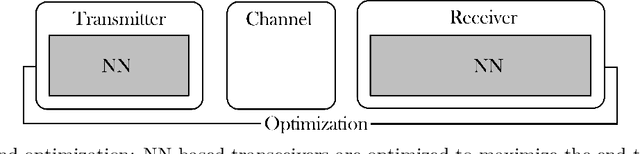
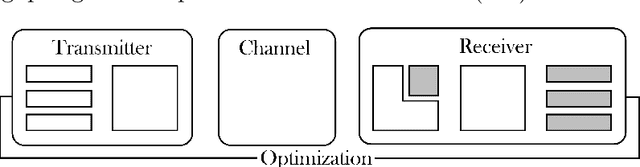

Innovation in the physical layer of communication systems has traditionally been achieved by breaking down the transceivers into sets of processing blocks, each optimized independently based on mathematical models. Conversely, deep learning (DL)-based systems are able to handle increasingly complex tasks for which no tractable models are available. This thesis aims at comparing different approaches to unlock the full potential of DL in the physical layer. First, we describe a neural network (NN)-based block strategy, where an NN is optimized to replace a block in a communication system. We apply this strategy to introduce a multi-user multiple-input multiple-output (MU-MIMO) detector that builds on top of an existing DL-based architecture. Second, we detail an end-to-end strategy, in which the transmitter and receiver are modeled as an autoencoder. This approach is illustrated with the design of waveforms that achieve high throughputs while satisfying peak-to-average power ratio (PAPR) and adjacent channel leakage ratio (ACLR) constraints. Lastly, we propose a hybrid strategy, where multiple DL components are inserted into a traditional architecture but are trained to optimize the end-to-end performance. To demonstrate its benefits, we propose a DL-enhanced MU-MIMO receiver that both enable lower bit error rates (BERs) compared to a conventional receiver and remains scalable to any number of users. Each approach has its own strengths and shortcomings. While the first one is the easiest to implement, its individual block optimization does not ensure the overall system optimality. On the other hand, systems designed with the second approach are computationally complex but allow for new opportunities such as pilotless transmissions. Finally, the combined flexibility and end-to-end performance gains of the third approach motivate its use for short-term practical implementations.
Learning OFDM Waveforms with PAPR and ACLR Constraints
Oct 21, 2021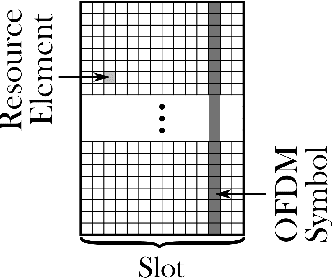
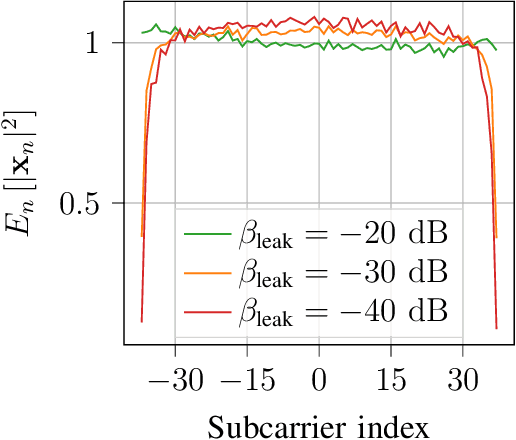
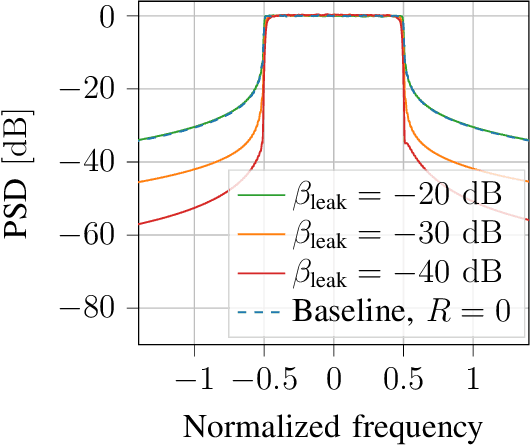
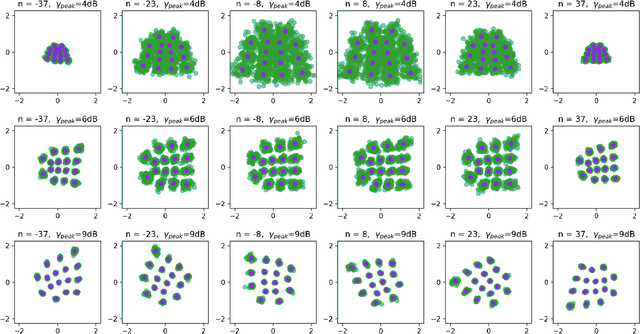
An attractive research direction for future communication systems is the design of new waveforms that can both support high throughputs and present advantageous signal characteristics. Although most modern systems use orthogonal frequency-division multiplexing (OFDM) for its efficient equalization, this waveform suffers from multiple limitations such as a high adjacent channel leakage ratio (ACLR) and high peak-to-average power ratio (PAPR). In this paper, we propose a learning-based method to design OFDM-based waveforms that satisfy selected constraints while maximizing an achievable information rate. To that aim, we model the transmitter and the receiver as convolutional neural networks (CNNs) that respectively implement a high-dimensional modulation scheme and perform the detection of the transmitted bits. This leads to an optimization problem that is solved using the augmented Lagrangian method. Evaluation results show that the end-to-end system is able to satisfy target PAPR and ACLR constraints and allows significant throughput gains compared to a tone reservation (TR) baseline. An additional advantage is that no dedicated pilots are needed.
Machine Learning-enhanced Receive Processing for MU-MIMO OFDM Systems
Jun 30, 2021
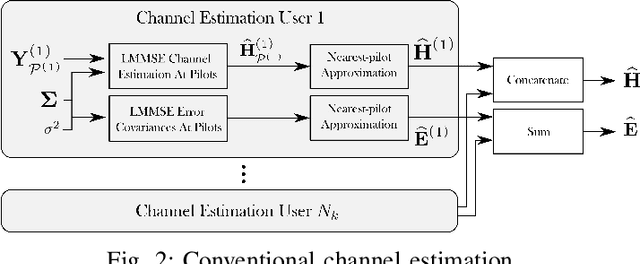
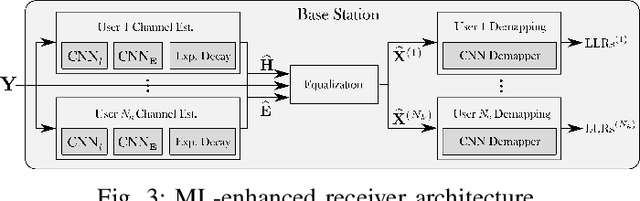
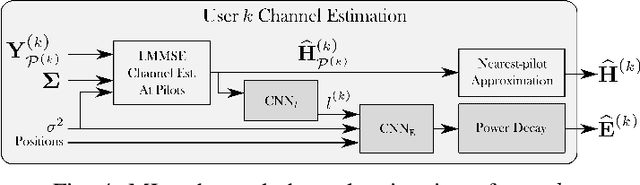
Machine learning (ML) can be used in various ways to improve multi-user multiple-input multiple-output (MU-MIMO) receive processing. Typical approaches either augment a single processing step, such as symbol detection, or replace multiple steps jointly by a single neural network (NN). These techniques demonstrate promising results but often assume perfect channel state information (CSI) or fail to satisfy the interpretability and scalability constraints imposed by practical systems. In this paper, we propose a new strategy which preserves the benefits of a conventional receiver, but enhances specific parts with ML components. The key idea is to exploit the orthogonal frequency-division multiplexing (OFDM) signal structure to improve both the demapping and the computation of the channel estimation error statistics. Evaluation results show that the proposed ML-enhanced receiver beats practical baselines on all considered scenarios, with significant gains at high speeds.
End-to-End Learning of OFDM Waveforms with PAPR and ACLR Constraints
Jun 30, 2021
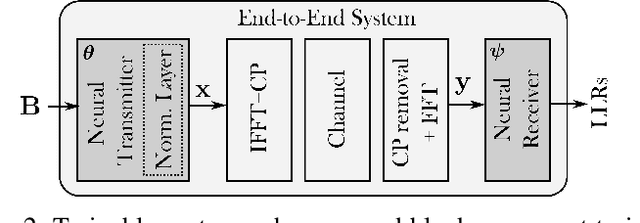
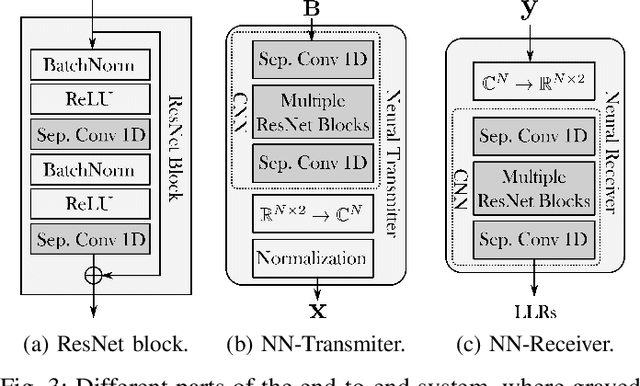
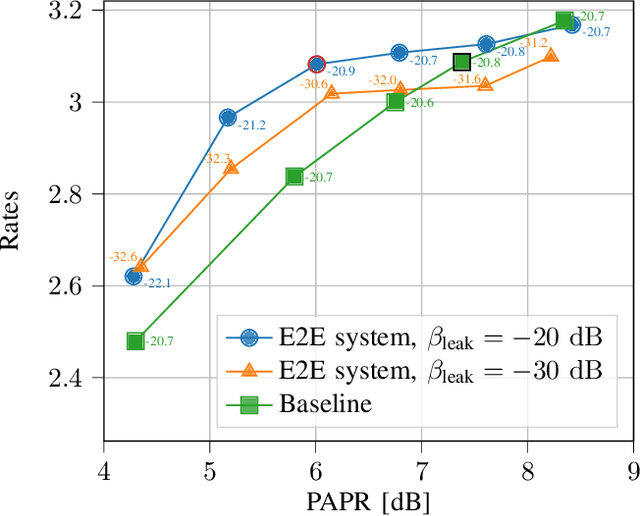
Orthogonal frequency-division multiplexing (OFDM) is widely used in modern wireless networks thanks to its efficient handling of multipath environment. However, it suffers from a poor peak-to-average power ratio (PAPR) which requires a large power backoff, degrading the power amplifier (PA) efficiency. In this work, we propose to use a neural network (NN) at the transmitter to learn a high-dimensional modulation scheme allowing to control the PAPR and adjacent channel leakage ratio (ACLR). On the receiver side, a NN-based receiver is implemented to carry out demapping of the transmitted bits. The two NNs operate on top of OFDM, and are jointly optimized in and end-to-end manner using a training algorithm that enforces constraints on the PAPR and ACLR. Simulation results show that the learned waveforms enable higher information rates than a tone reservation baseline, while satisfying predefined PAPR and ACLR targets.
Machine Learning for MU-MIMO Receive Processing in OFDM Systems
Dec 15, 2020
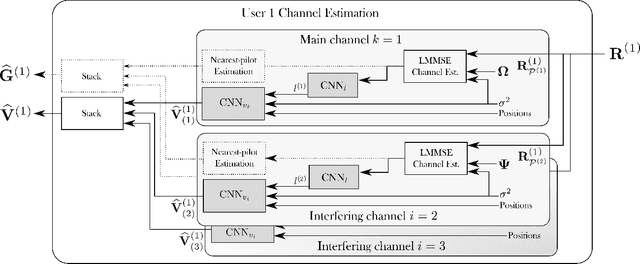

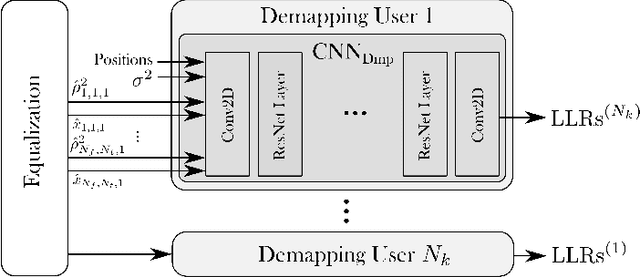
Machine learning (ML) starts to be widely used to enhance the performance of multi-user multiple-input multiple-output (MU-MIMO) receivers. However, it is still unclear if such methods are truly competitive with respect to conventional methods in realistic scenarios and under practical constraints. In addition to enabling accurate signal reconstruction on realistic channel models, MU-MIMO receive algorithms must allow for easy adaptation to a varying number of users without the need for retraining. In contrast to existing work, we propose an ML-enhanced MU-MIMO receiver that builds on top of a conventional linear minimum mean squared error (LMMSE) architecture. It preserves the interpretability and scalability of the LMMSE receiver, while improving its accuracy in two ways. First, convolutional neural networks (CNNs) are used to compute an approximation of the second-order statistics of the channel estimation error which are required for accurate equalization. Second, a CNN-based demapper jointly processes a large number of orthogonal frequency-division multiplexing (OFDM) symbols and subcarriers, which allows it to compute better log likelihood ratios (LLRs) by compensating for channel aging. The resulting architecture can be used in the up- and downlink and is trained in an end-to-end manner, removing the need for hard-to-get perfect channel state information (CSI) during the training phase. Simulation results demonstrate consistent performance improvements over the baseline which are especially pronounced in high mobility scenarios.
Deep HyperNetwork-Based MIMO Detection
Feb 10, 2020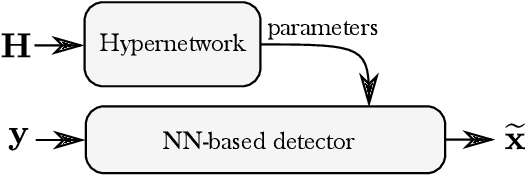
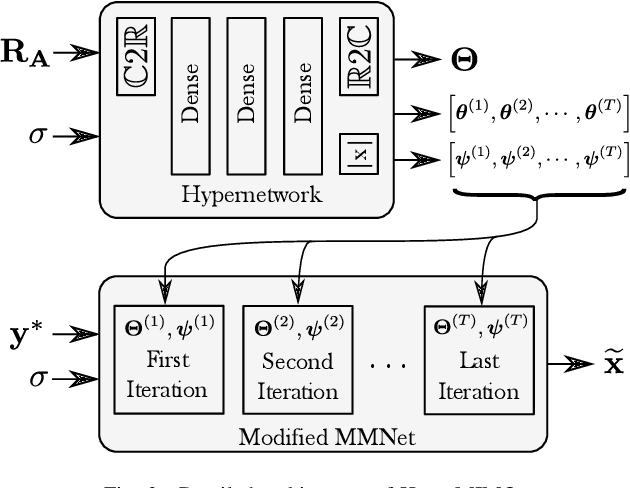
Optimal symbol detection for multiple-input multiple-output (MIMO) systems is known to be an NP-hard problem. Conventional heuristic algorithms are either too complex to be practical or suffer from poor performance. Recently, several approaches tried to address those challenges by implementing the detector as a deep neural network. However, they either still achieve unsatisfying performance on practical spatially correlated channels, or are computationally demanding since they require retraining for each channel realization. In this work, we address both issues by training an additional neural network (NN), referred to as the hypernetwork, which takes as input the channel matrix and generates the weights of the neural NN-based detector. Results show that the proposed approach achieves near state-of-the-art performance without the need for re-training.