 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Representations via Mutual Information Estimation
Dec 09, 2019
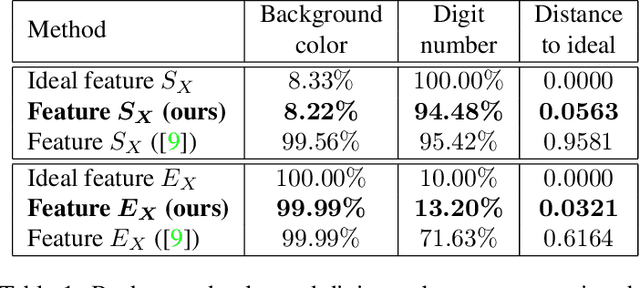
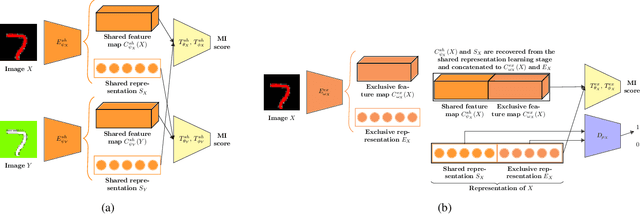
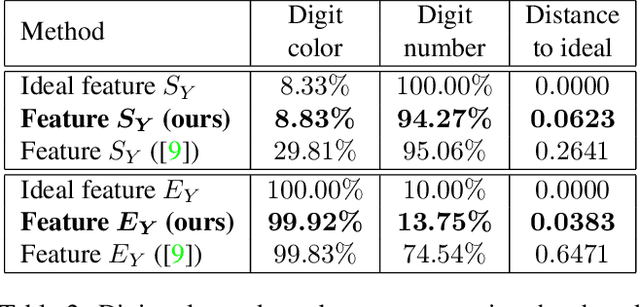
In this paper, we investigate the problem of learning disentangled representations. Given a pair of images sharing some attributes, we aim to create a low-dimensional representation which is split into two parts: a shared representation that captures the common information between the images and an exclusive representation that contains the specific information of each image. To address this issue, we propose a model based on mutual information estimation without relying on image reconstruction or image generation. Mutual information maximization is performed to capture the attributes of data in the shared and exclusive representations while we minimize the mutual information between the shared and exclusive representation to enforce representation disentanglement. We show that these representations are useful to perform downstream tasks such as image classification and image retrieval based on the shared or exclusive component. Moreover, classification results show that our model outperforms the state-of-the-art model based on VAE/GAN approaches in representation disentanglement.
Learning Disentangled Representations of Satellite Image Time Series
Mar 21, 2019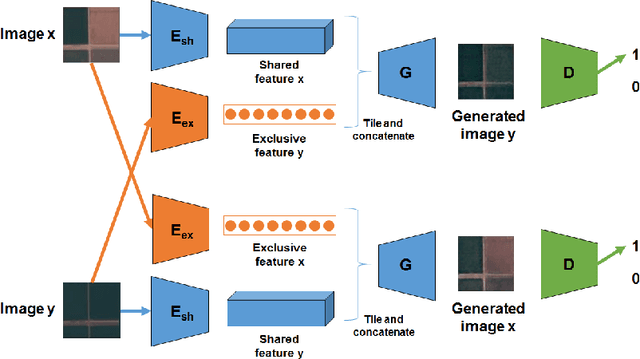

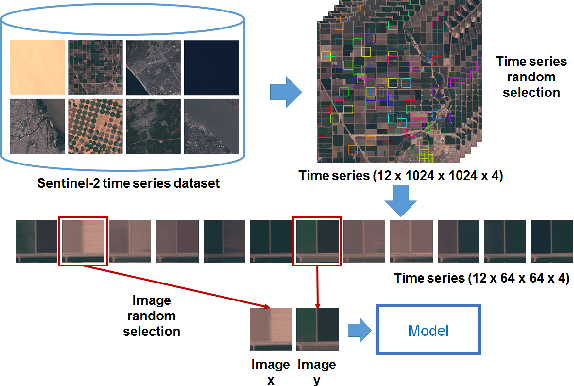

In this paper, we investigate how to learn a suitable representation of satellite image time series in an unsupervised manner by leveraging large amounts of unlabeled data. Additionally , we aim to disentangle the representation of time series into two representations: a shared representation that captures the common information between the images of a time series and an exclusive representation that contains the specific information of each image of the time series. To address these issues, we propose a model that combines a novel component called cross-domain autoencoders with the variational autoencoder (VAE) and generative ad-versarial network (GAN) methods. In order to learn disentangled representations of time series, our model learns the multimodal image-to-image translation task. We train our model using satellite image time series from the Sentinel-2 mission. Several experiments are carried out to evaluate the obtained representations. We show that these disentangled representations can be very useful to perform multiple tasks such as image classification, image retrieval, image segmentation and change detection.