 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding up Word Mover's Distance and its variants via properties of distances between embeddings
Dec 01, 2019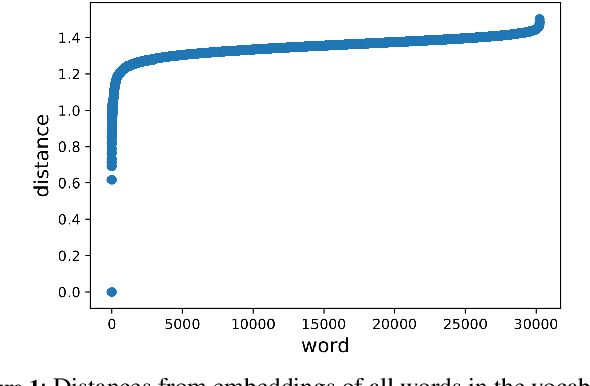
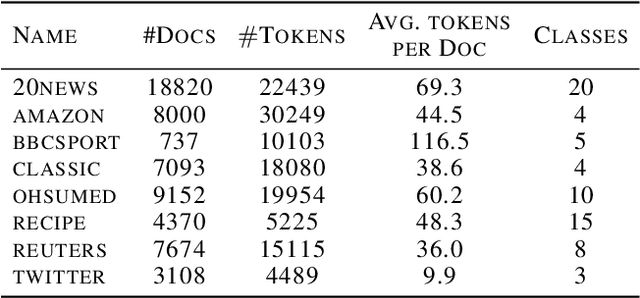
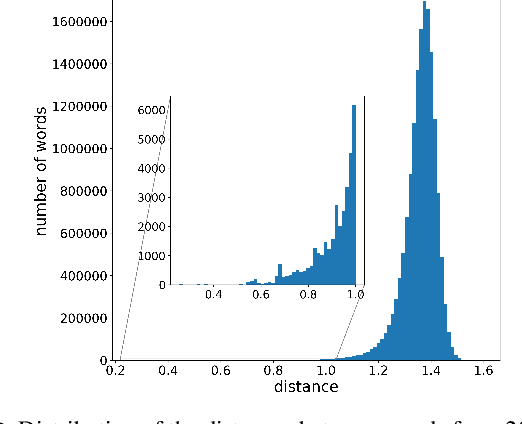
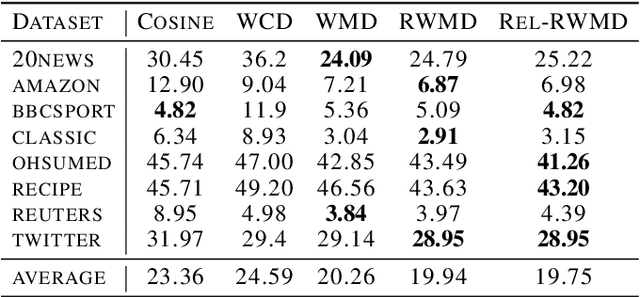
The Word Mover's Distance (WMD) proposed in Kusner et al. [ICML,2015] is a distance between documents that takes advantage of semantic relations among words that are captured by their embeddings. This distance proved to be quite effective, obtaining state-of-art error rates for classification tasks, but also impracticable for large collections/documents due to its computational complexity. For circumventing this problem, variants of WMD have been proposed. Among them, Relaxed Word Mover's Distance (RWMD) is one of the most successful due to its simplicity, effectiveness, and also because of its fast implementations. Relying on assumptions that are supported by empirical properties of the distances between embeddings, we propose an approach to speed up both WMD and RWMD. Experiments over 10 datasets suggest that our approach leads to a significant speed-up in document classification tasks while maintaining the same error rates.