 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobiprox: Supporting Dynamic Approximate Computing on Mobiles
Mar 16, 2023
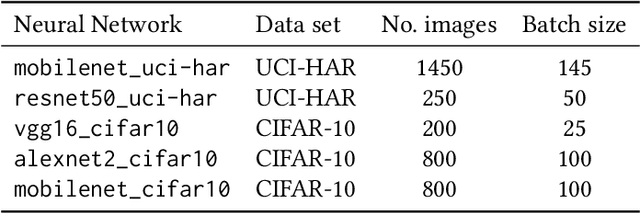
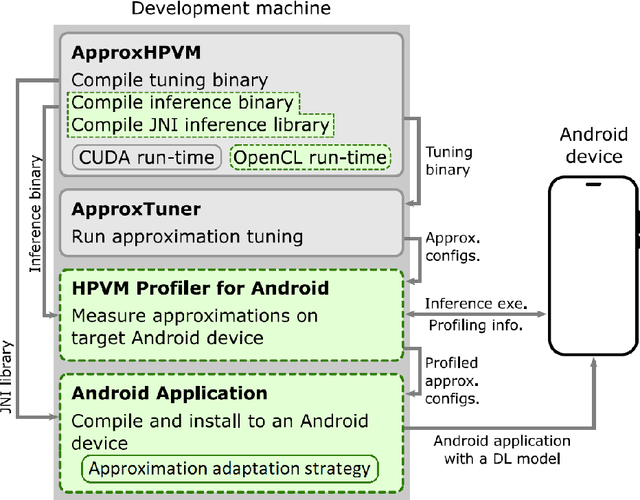
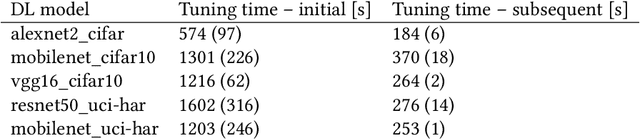
Runtime-tunable context-dependent network compression would make mobile deep learning adaptable to often varying resource availability, input "difficulty", or user needs. The existing compression techniques significantly reduce the memory, processing, and energy tax of deep learning, yet, the resulting models tend to be permanently impaired, sacrificing the inference power for reduced resource usage. The existing tunable compression approaches, on the other hand, require expensive re-training, seldom provide mobile-ready implementations, and do not support arbitrary strategies for adapting the compression. In this paper we present Mobiprox, a framework enabling flexible-accuracy on-device deep learning. Mobiprox implements tunable approximations of tensor operations and enables runtime adaptation of individual network layers. A profiler and a tuner included with Mobiprox identify the most promising neural network approximation configurations leading to the desired inference quality with the minimal use of resources. Furthermore, we develop control strategies that depending on contextual factors, such as the input data difficulty, dynamically adjust the approximation level of a model. We implement Mobiprox in Android OS and through experiments in diverse mobile domains, including human activity recognition and spoken keyword detection, demonstrate that it can save up to 15% system-wide energy with a minimal impact on the inference accuracy.