 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-enhanced tuning of quantum dot Hamiltonians toward Majorana modes
Jan 05, 2026We propose a neural network-based model capable of learning the broad landscape of working regimes in quantum dot simulators, and using this knowledge to autotune these devices - based on transport measurements - toward obtaining Majorana modes in the structure. The model is trained in an unsupervised manner on synthetic data in the form of conductance maps, using a physics-informed loss that incorporates key properties of Majorana zero modes. We show that, with appropriate training, a deep vision-transformer network can efficiently memorize relation between Hamiltonian parameters and structures on conductance maps and use it to propose parameters update for a quantum dot chain that drive the system toward topological phase. Starting from a broad range of initial detunings in parameter space, a single update step is sufficient to generate nontrivial zero modes. Moreover, by enabling an iterative tuning procedure - where the system acquires updated conductance maps at each step - we demonstrate that the method can address a much larger region of the parameter space.
Data-driven criteria for quantum correlations
Jul 20, 2023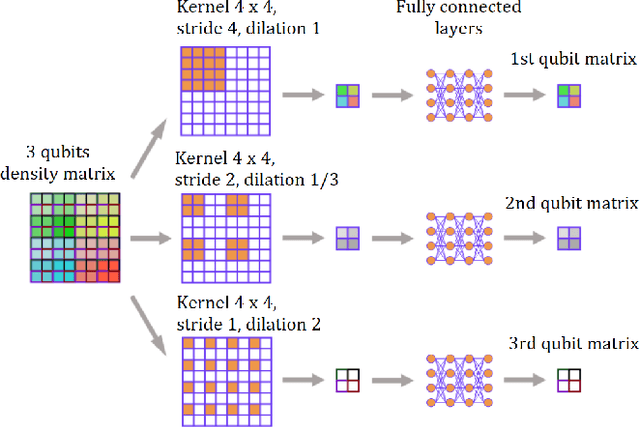
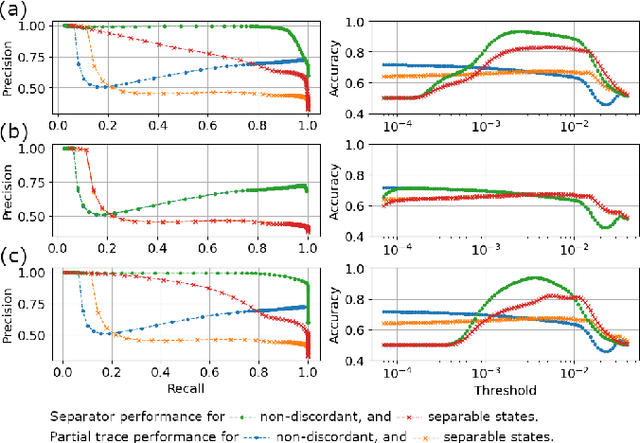
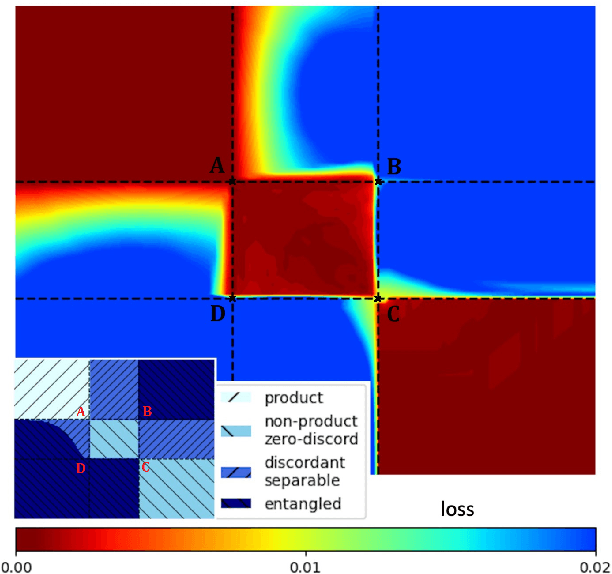

We build a machine learning model to detect correlations in a three-qubit system using a neural network trained in an unsupervised manner on randomly generated states. The network is forced to recognize separable states, and correlated states are detected as anomalies. Quite surprisingly, we find that the proposed detector performs much better at distinguishing a weaker form of quantum correlations, namely, the quantum discord, than entanglement. In fact, it has a tendency to grossly overestimate the set of entangled states even at the optimal threshold for entanglement detection, while it underestimates the set of discordant states to a much lesser extent. In order to illustrate the nature of states classified as quantum-correlated, we construct a diagram containing various types of states -- entangled, as well as separable, both discordant and non-discordant. We find that the near-zero value of the recognition loss reproduces the shape of the non-discordant separable states with high accuracy, especially considering the non-trivial shape of this set on the diagram. The network architecture is designed carefully: it preserves separability, and its output is equivariant with respect to qubit permutations. We show that the choice of architecture is important to get the highest detection accuracy, much better than for a baseline model that just utilizes a partial trace operation.
Quantification of entanglement with Siamese convolutional neural networks
Oct 13, 2022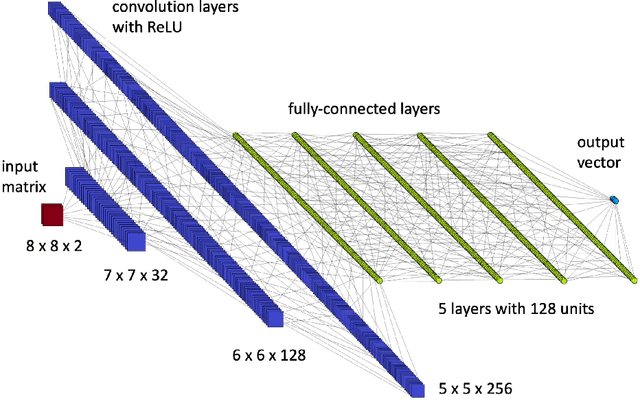

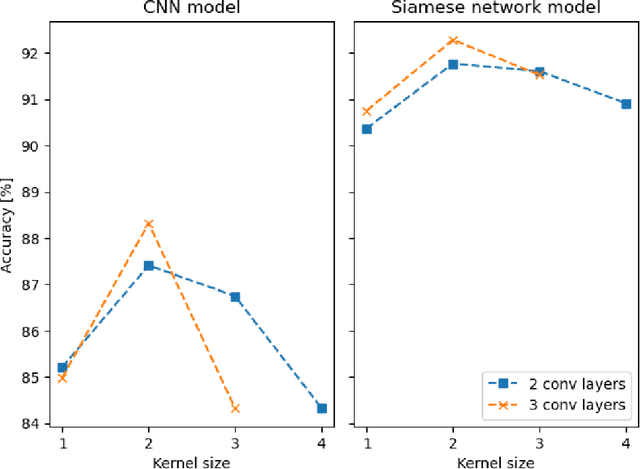
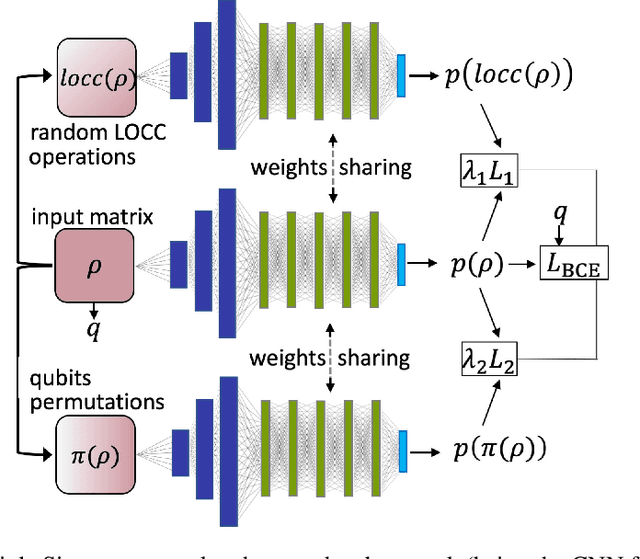
Quantum entanglement is a fundamental property commonly used in various quantum information protocols and algorithms. Nonetheless, the problem of quantifying entanglement has still not reached general solution for systems larger than two qubits. In this paper, we investigate the possibility of detecting entanglement with the use of the supervised machine learning method, namely the deep convolutional neural networks. We build a model consisting of convolutional layers, which is able to recognize and predict the presence of entanglement for any bipartition of the given multi-qubit system. We demonstrate that training our model on synthetically generated datasets collecting random density matrices, which either include or exclude challenging positive-under-partial-transposition entangled states (PPTES), leads to the different accuracy of the model and its possibility to detect such states. Moreover, it is shown that enforcing entanglement-preserving symmetry operations (local operations on qubit or permutations of qubits) by using triple Siamese network, can significantly increase the model performance and ability to generalize on types of states not seen during the training stage. We perform numerical calculations for 3,4 and 5-qubit systems, therefore proving the scalability of the proposed approach.