 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Repetition Improves Non-Reasoning LLMs
Dec 17, 2025When not using reasoning, repeating the input prompt improves performance for popular models (Gemini, GPT, Claude, and Deepseek) without increasing the number of generated tokens or latency.
Selective Attention Improves Transformer
Oct 03, 2024
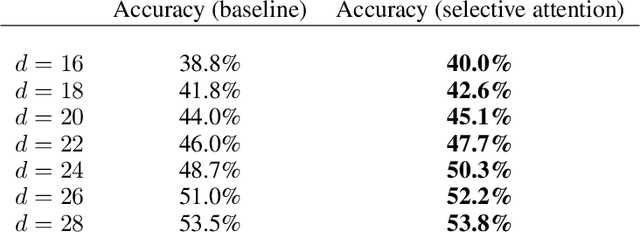


Unneeded elements in the attention's context degrade performance. We introduce Selective Attention, a simple parameter-free change to the standard attention mechanism which reduces attention to unneeded elements. Selective attention improves language modeling performance in a variety of model sizes and context lengths. For example, a range of transformers trained with the language modeling objective on C4 with selective attention perform equivalently to standard transformers with ~2X more heads and parameters in their attention modules. Selective attention also allows decreasing the size of the attention's context buffer, leading to meaningful reductions in the memory and compute requirements during inference. For example, transformers with 100M parameters trained on C4 with context sizes of 512, 1,024, and 2,048 need 16X, 25X, and 47X less memory for their attention module, respectively, when equipped with selective attention, as those without selective attention, with the same validation perplexity.
Fast Inference from Transformers via Speculative Decoding
Nov 30, 2022



Inference from large autoregressive models like Transformers is slow - decoding K tokens takes K serial runs of the model. In this work we introduce speculative decoding - an algorithm to sample from autoregressive models faster without any changes to the outputs, by computing several tokens in parallel. At the heart of our approach lie the observations that (1) hard language-modeling tasks often include easier subtasks that can be approximated well by more efficient models, and (2) using speculative execution and a novel sampling method, we can make exact decoding from the large models faster, by running them in parallel on the outputs of the approximation models, potentially generating several tokens concurrently, and without changing the distribution. Our method supports existing off-the-shelf models without retraining or architecture changes. We demonstrate it on T5-XXL and show a 2X-3X acceleration compared to the standard T5X implementation, with identical outputs.
UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image
Oct 20, 2022
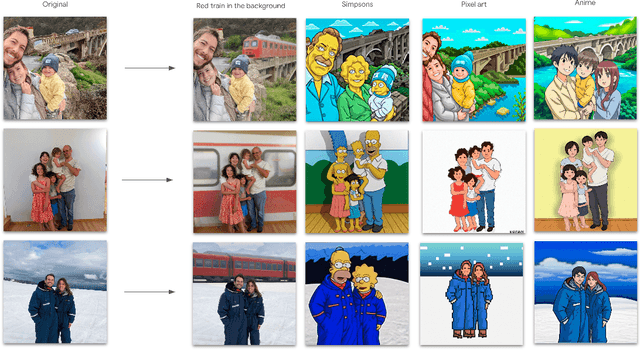


We present UniTune, a simple and novel method for general text-driven image editing. UniTune gets as input an arbitrary image and a textual edit description, and carries out the edit while maintaining high semantic and visual fidelity to the input image. UniTune uses text, an intuitive interface for art-direction, and does not require additional inputs, like masks or sketches. At the core of our method is the observation that with the right choice of parameters, we can fine-tune a large text-to-image diffusion model on a single image, encouraging the model to maintain fidelity to the input image while still allowing expressive manipulations. We used Imagen as our text-to-image model, but we expect UniTune to work with other large-scale models as well. We test our method in a range of different use cases, and demonstrate its wide applicability.