 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse and Styled Image Captioning Using SVD-Based Mixture of Recurrent Experts
Jul 07, 2020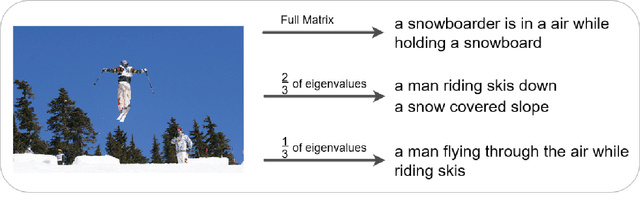
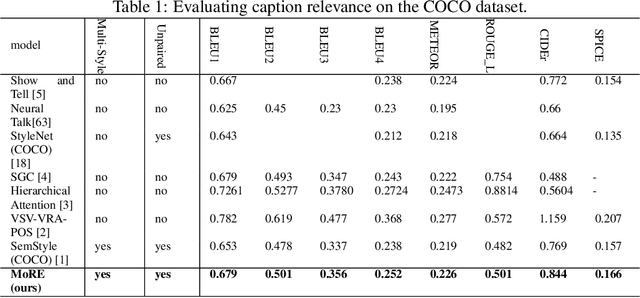
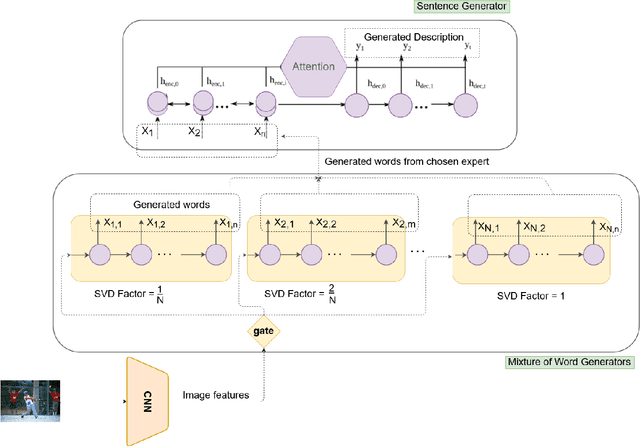

With great advances in vision and natural language processing, the generation of image captions becomes a need. In a recent paper, Mathews, Xie and He [1], extended a new model to generate styled captions by separating semantics and style. In continuation of this work, here a new captioning model is developed including an image encoder to extract the features, a mixture of recurrent networks to embed the set of extracted features to a set of words, and a sentence generator that combines the obtained words as a stylized sentence. The resulted system that entitled as Mixture of Recurrent Experts (MoRE), uses a new training algorithm that derives singular value decomposition (SVD) from weighting matrices of Recurrent Neural Networks (RNNs) to increase the diversity of captions. Each decomposition step depends on a distinctive factor based on the number of RNNs in MoRE. Since the used sentence generator gives a stylized language corpus without paired images, our captioning model can do the same. Besides, the styled and diverse captions are extracted without training on a densely labeled or styled dataset. To validate this captioning model, we use Microsoft COCO which is a standard factual image caption dataset. We show that the proposed captioning model can generate a diverse and stylized image captions without the necessity of extra-labeling. The results also show better descriptions in terms of content accuracy.