 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Analysis on Machine Learning based Methods for Lung Cancer Level Classification
Jan 30, 2025Lung cancer is a major issue in worldwide public health, requiring early diagnosis using stable techniques. This work begins a thorough investigation of the use of machine learning (ML) methods for precise classification of lung cancer stages. A cautious analysis is performed to overcome overfitting issues in model performance, taking into account minimum child weight and learning rate. A set of machine learning (ML) models including XGBoost (XGB), LGBM, Adaboost, Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), CatBoost, and k-Nearest Neighbor (k-NN) are run methodically and contrasted. Furthermore, the correlation between features and targets is examined using the deep neural network (DNN) model and thus their capability in detecting complex patternsis established. It is argued that several ML models can be capable of classifying lung cancer stages with great accuracy. In spite of the complexity of DNN architectures, traditional ML models like XGBoost, LGBM, and Logistic Regression excel with superior performance. The models perform better than the others in lung cancer prediction on the complete set of comparative metrics like accuracy, precision, recall, and F-1 score
CNN-based Labelled Crack Detection for Image Annotation
Aug 21, 2024
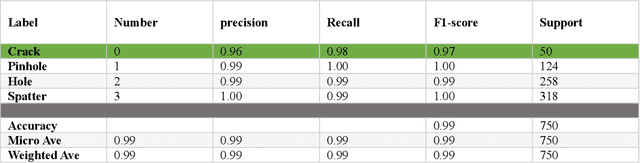


Numerous image processing techniques (IPTs) have been employed to detect crack defects, offering an alternative to human-conducted onsite inspections. These IPTs manipulate images to extract defect features, particularly cracks in surfaces produced through Additive Manufacturing (AM). This article presents a vision-based approach that utilizes deep convolutional neural networks (CNNs) for crack detection in AM surfaces. Traditional image processing techniques face challenges with diverse real-world scenarios and varying crack types. To overcome these challenges, our proposed method leverages CNNs, eliminating the need for extensive feature extraction. Annotation for CNN training is facilitated by LabelImg without the requirement for additional IPTs. The trained CNN, enhanced by OpenCV preprocessing techniques, achieves an outstanding 99.54% accuracy on a dataset of 14,982 annotated images with resolutions of 1536 x 1103 pixels. Evaluation metrics exceeding 96% precision, 98% recall, and a 97% F1-score highlight the precision and effectiveness of the entire process.