 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraud Detection Using Optimized Machine Learning Tools Under Imbalance Classes
Sep 04, 2022
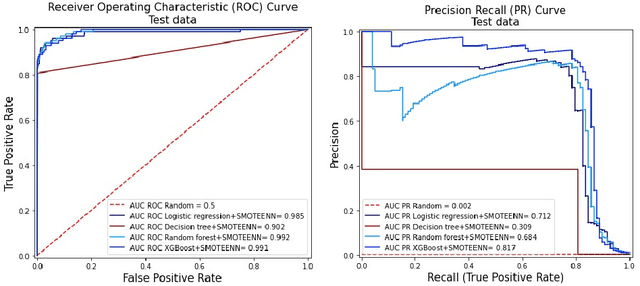
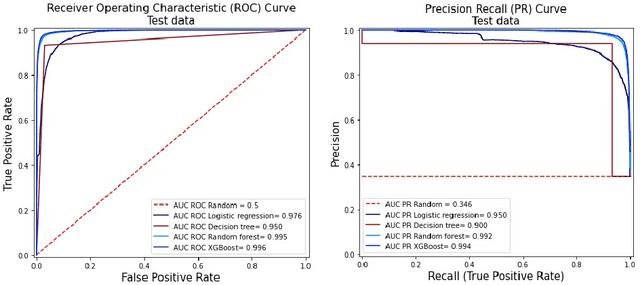
Fraud detection is a challenging task due to the changing nature of fraud patterns over time and the limited availability of fraud examples to learn such sophisticated patterns. Thus, fraud detection with the aid of smart versions of machine learning (ML) tools is essential to assure safety. Fraud detection is a primary ML classification task; however, the optimum performance of the corresponding ML tool relies on the usage of the best hyperparameter values. Moreover, classification under imbalanced classes is quite challenging as it causes poor performance in minority classes, which most ML classification techniques ignore. Thus, we investigate four state-of-the-art ML techniques, namely, logistic regression, decision trees, random forest, and extreme gradient boost, that are suitable for handling imbalance classes to maximize precision and simultaneously reduce false positives. First, these classifiers are trained on two original benchmark unbalanced fraud detection datasets, namely, phishing website URLs and fraudulent credit card transactions. Then, three synthetically balanced datasets are produced for each original data set by implementing the sampling frameworks, namely, RandomUnderSampler, SMOTE, and SMOTEENN. The optimum hyperparameters for all the 16 experiments are revealed using the method RandomzedSearchCV. The validity of the 16 approaches in the context of fraud detection is compared using two benchmark performance metrics, namely, area under the curve of receiver operating characteristics (AUC ROC) and area under the curve of precision and recall (AUC PR). For both phishing website URLs and credit card fraud transaction datasets, the results indicate that extreme gradient boost trained on the original data shows trustworthy performance in the imbalanced dataset and manages to outperform the other three methods in terms of both AUC ROC and AUC PR.