 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenalized estimation in large-scale generalized linear array models
Sep 02, 2016
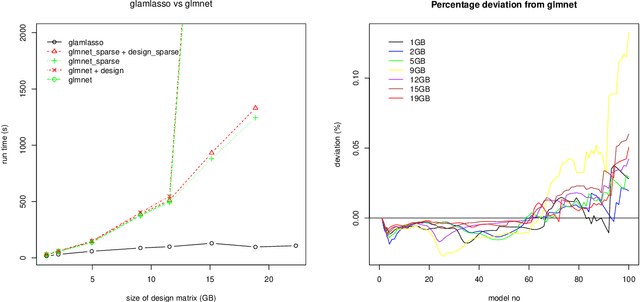
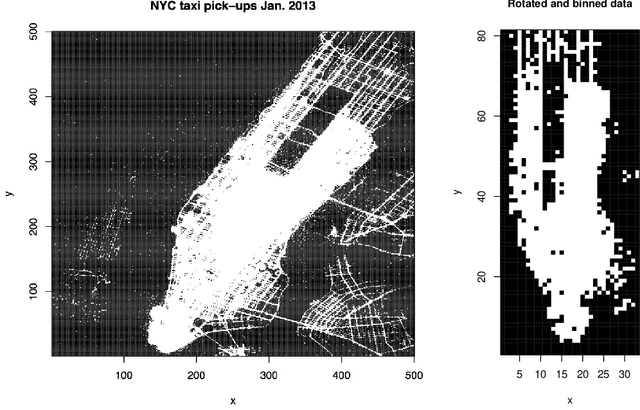
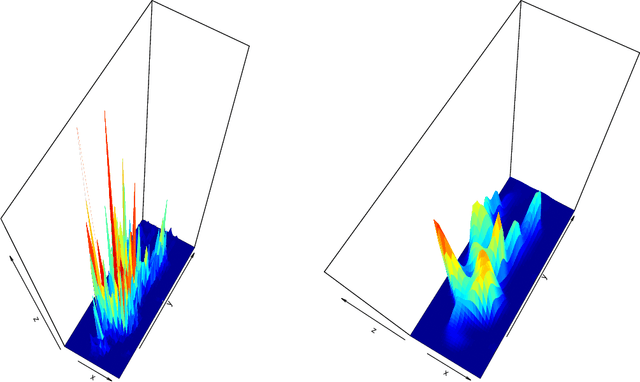
Large-scale generalized linear array models (GLAMs) can be challenging to fit. Computation and storage of its tensor product design matrix can be impossible due to time and memory constraints, and previously considered design matrix free algorithms do not scale well with the dimension of the parameter vector. A new design matrix free algorithm is proposed for computing the penalized maximum likelihood estimate for GLAMs, which, in particular, handles nondifferentiable penalty functions. The proposed algorithm is implemented and available via the R package \verb+glamlasso+. It combines several ideas -- previously considered separately -- to obtain sparse estimates while at the same time efficiently exploiting the GLAM structure. In this paper the convergence of the algorithm is treated and the performance of its implementation is investigated and compared to that of \verb+glmnet+ on simulated as well as real data. It is shown that the computation time for
Sparse group lasso and high dimensional multinomial classification
Feb 06, 2013
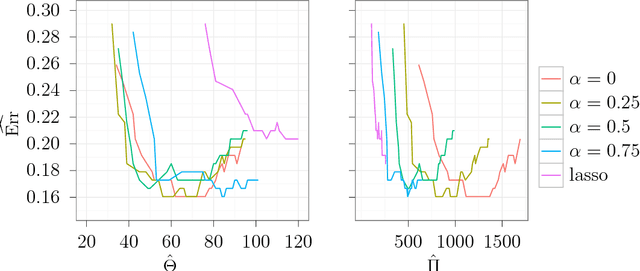

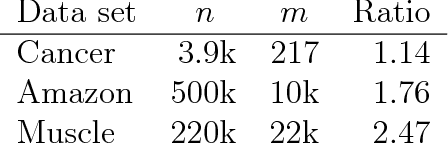
The sparse group lasso optimization problem is solved using a coordinate gradient descent algorithm. The algorithm is applicable to a broad class of convex loss functions. Convergence of the algorithm is established, and the algorithm is used to investigate the performance of the multinomial sparse group lasso classifier. On three different real data examples the multinomial group lasso clearly outperforms multinomial lasso in terms of achieved classification error rate and in terms of including fewer features for the classification. The run-time of our sparse group lasso implementation is of the same order of magnitude as the multinomial lasso algorithm implemented in the R package glmnet. Our implementation scales well with the problem size. One of the high dimensional examples considered is a 50 class classification problem with 10k features, which amounts to estimating 500k parameters. The implementation is available as the R package msgl.