 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe IWSLT 2021 BUT Speech Translation Systems
Jul 13, 2021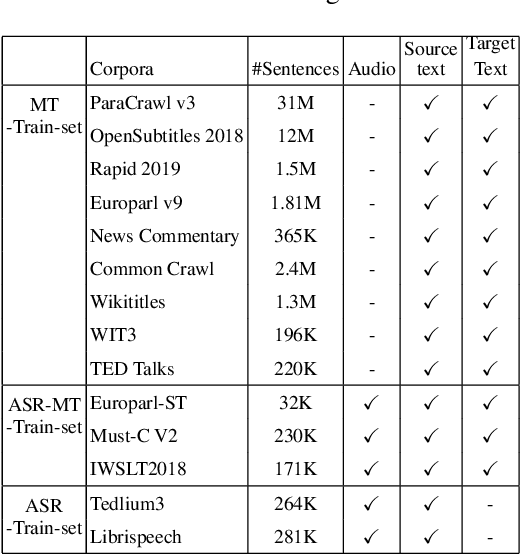
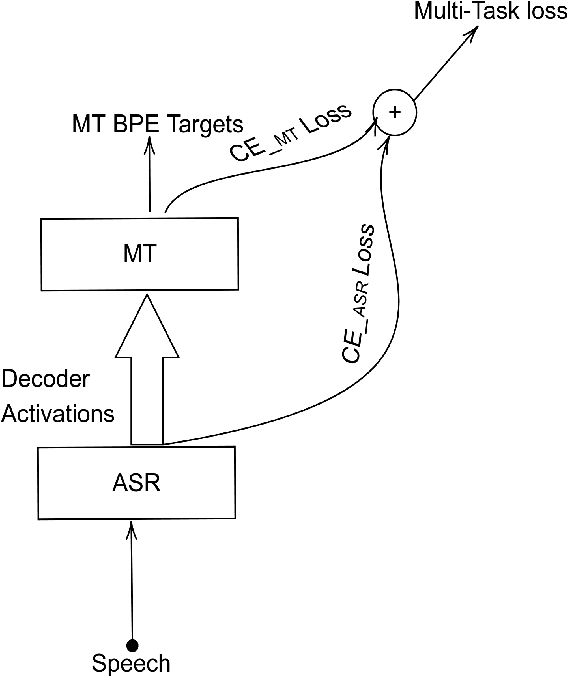
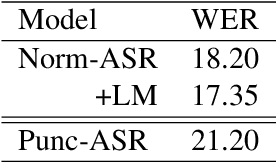
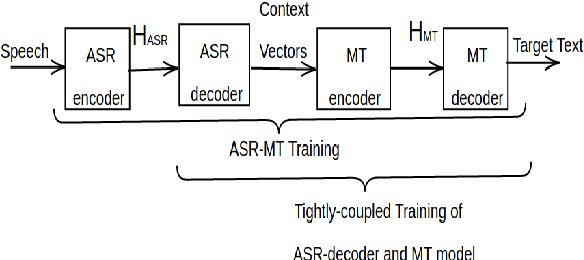
The paper describes BUT's English to German offline speech translation(ST) systems developed for IWSLT2021. They are based on jointly trained Automatic Speech Recognition-Machine Translation models. Their performances is evaluated on MustC-Common test set. In this work, we study their efficiency from the perspective of having a large amount of separate ASR training data and MT training data, and a smaller amount of speech-translation training data. Large amounts of ASR and MT training data are utilized for pre-training the ASR and MT models. Speech-translation data is used to jointly optimize ASR-MT models by defining an end-to-end differentiable path from speech to translations. For this purpose, we use the internal continuous representations from the ASR-decoder as the input to MT module. We show that speech translation can be further improved by training the ASR-decoder jointly with the MT-module using large amount of text-only MT training data. We also show significant improvements by training an ASR module capable of generating punctuated text, rather than leaving the punctuation task to the MT module.
Jointly Trained Transformers models for Spoken Language Translation
Apr 25, 2020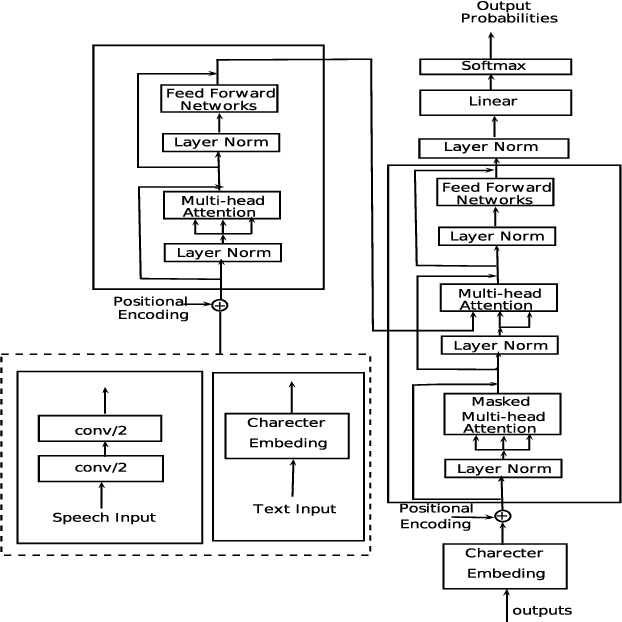
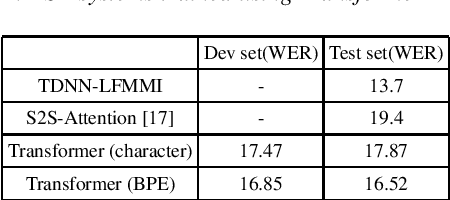
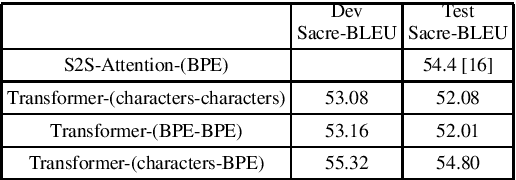
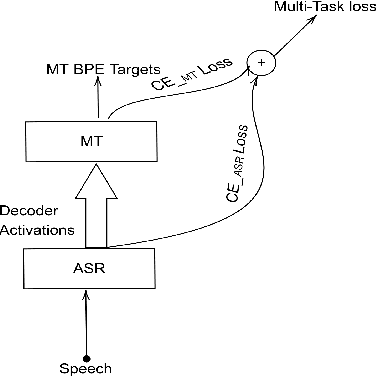
Conventional spoken language translation (SLT) systems are pipeline based systems, where we have an Automatic Speech Recognition (ASR) system to convert the modality of source from speech to text and a Machine Translation (MT) systems to translate source text to text in target language. Recent progress in the sequence-sequence architectures have reduced the performance gap between the pipeline based SLT systems (cascaded ASR-MT) and End-to-End approaches. Though End-to-End and cascaded ASR-MT systems are reaching to the comparable levels of performances, we can see a large performance gap using the ASR hypothesis and oracle text w.r.t MT models. This performance gap indicates that the MT systems are prone to large performance degradation due to noisy ASR hypothesis as opposed to oracle text transcript. In this work this degradation in the performance is reduced by creating an end to-end differentiable pipeline between the ASR and MT systems. In this work, we train SLT systems with ASR objective as an auxiliary loss and both the networks are connected through the neural hidden representations. This train ing would have an End-to-End differentiable path w.r.t to the final objective function as well as utilize the ASR objective for better performance of the SLT systems. This architecture has improved from BLEU from 36.8 to 44.5. Due to the Multi-task training the model also generates the ASR hypothesis which are used by a pre-trained MT model. Combining the proposed systems with the MT model has increased the BLEU score by 1. All the experiments are reported on English-Portuguese speech translation task using How2 corpus. The final BLEU score is on-par with the best speech translation system on How2 dataset with no additional training data and language model and much less parameters.