 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Chemicals Through Dimensionality Reduction
Nov 27, 2022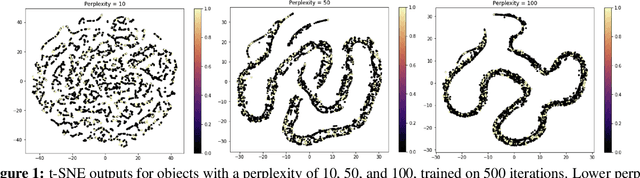
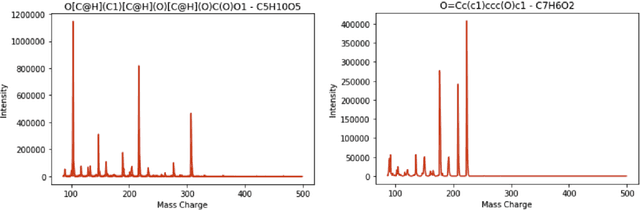
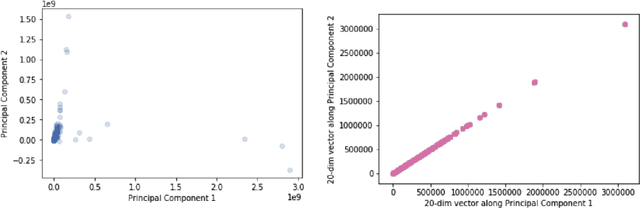

Civilizations have tried to make drinking water safe to consume for thousands of years. The process of determining water contaminants has evolved with the complexity of the contaminants due to pesticides and heavy metals. The routine procedure to determine water safety is to use targeted analysis which searches for specific substances from some known list; however, we do not explicitly know which substances should be on this list. Before experimentally determining which substances are contaminants, how do we answer the sampling problem of identifying all the substances in the water? Here, we present an approach that builds on the work of Jaanus Liigand et al., which used non-targeted analysis that conducts a broader search on the sample to develop a random-forest regression model, to predict the names of all the substances in a sample, as well as their respective concentrations[1]. This work utilizes techniques from dimensionality reduction and linear decompositions to present a more accurate model using data from the European Massbank Metabolome Library to produce a global list of chemicals that researchers can then identify and test for when purifying water.