 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Actor-Critic via TD Error Aggregation
Jul 25, 2022
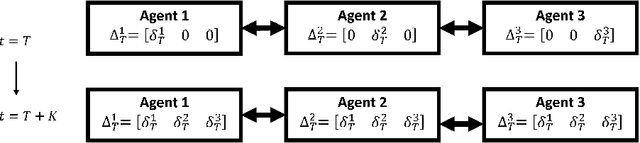
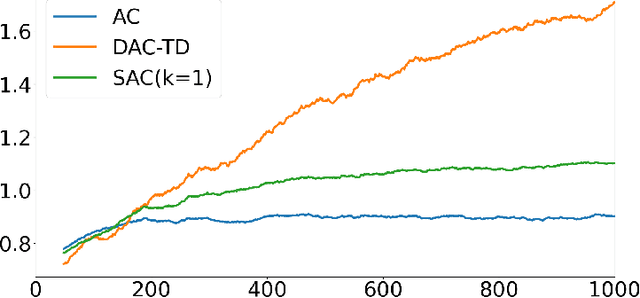
In decentralized cooperative multi-agent reinforcement learning, agents can aggregate information from one another to learn policies that maximize a team-average objective function. Despite the willingness to cooperate with others, the individual agents may find direct sharing of information about their local state, reward, and value function undesirable due to privacy issues. In this work, we introduce a decentralized actor-critic algorithm with TD error aggregation that does not violate privacy issues and assumes that communication channels are subject to time delays and packet dropouts. The cost we pay for making such weak assumptions is an increased communication burden for every agent as measured by the dimension of the transmitted data. Interestingly, the communication burden is only quadratic in the graph size, which renders the algorithm applicable in large networks. We provide a convergence analysis under diminishing step size to verify that the agents maximize the team-average objective function.
Resilient Consensus-based Multi-agent Reinforcement Learning with Function Approximation
Nov 18, 2021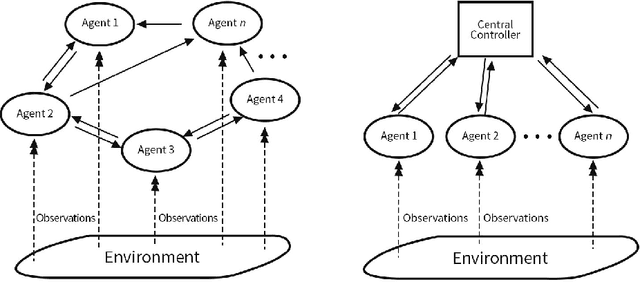
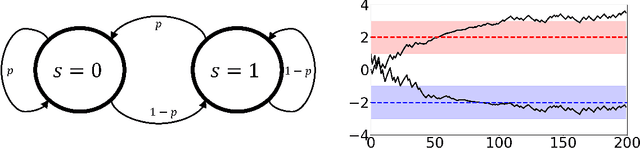
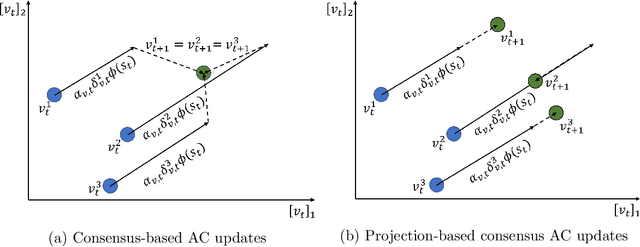
Adversarial attacks during training can strongly influence the performance of multi-agent reinforcement learning algorithms. It is, thus, highly desirable to augment existing algorithms such that the impact of adversarial attacks on cooperative networks is eliminated, or at least bounded. In this work, we consider a fully decentralized network, where each agent receives a local reward and observes the global state and action. We propose a resilient consensus-based actor-critic algorithm, whereby each agent estimates the team-average reward and value function, and communicates the associated parameter vectors to its immediate neighbors. We show that in the presence of Byzantine agents, whose estimation and communication strategies are completely arbitrary, the estimates of the cooperative agents converge to a bounded consensus value with probability one, provided that there are at most $H$ Byzantine agents in the neighborhood of each cooperative agent and the network is $(2H+1)$-robust. Furthermore, we prove that the policy of the cooperative agents converges with probability one to a bounded neighborhood around a local maximizer of their team-average objective function under the assumption that the policies of the adversarial agents asymptotically become stationary.
Adversarial attacks in consensus-based multi-agent reinforcement learning
Mar 11, 2021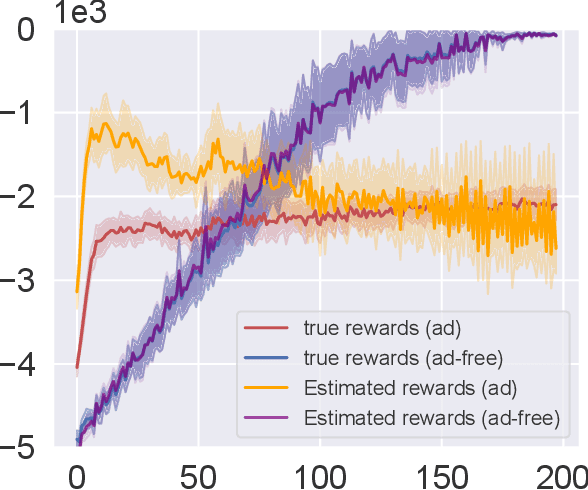
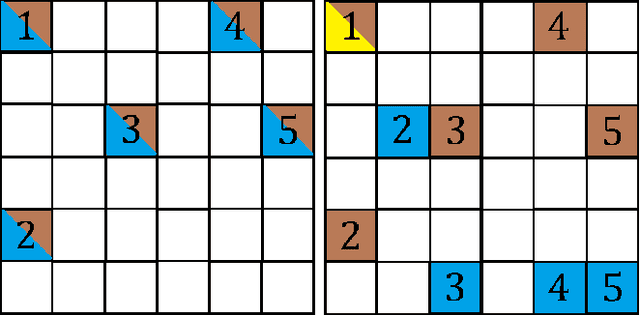
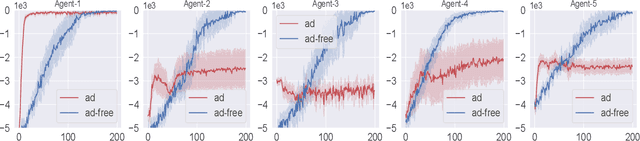
Recently, many cooperative distributed multi-agent reinforcement learning (MARL) algorithms have been proposed in the literature. In this work, we study the effect of adversarial attacks on a network that employs a consensus-based MARL algorithm. We show that an adversarial agent can persuade all the other agents in the network to implement policies that optimize an objective that it desires. In this sense, the standard consensus-based MARL algorithms are fragile to attacks.