 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP-based Decision Support System for Examination of Eligibility Criteria from Securities Prospectuses at the German Central Bank
Feb 09, 2023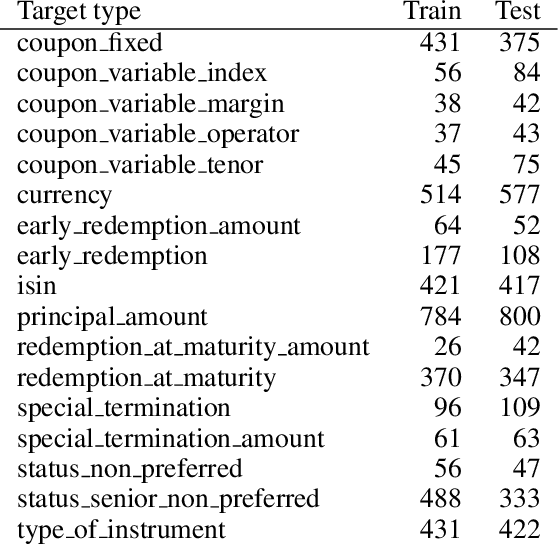
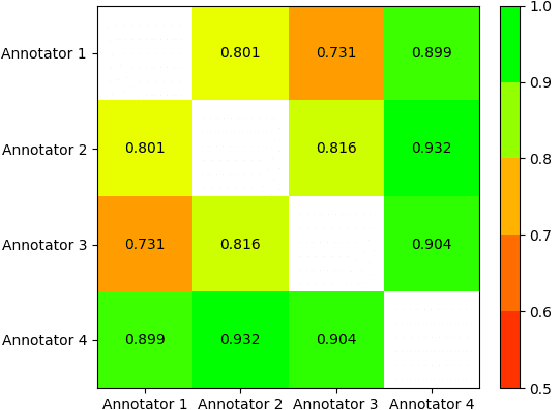
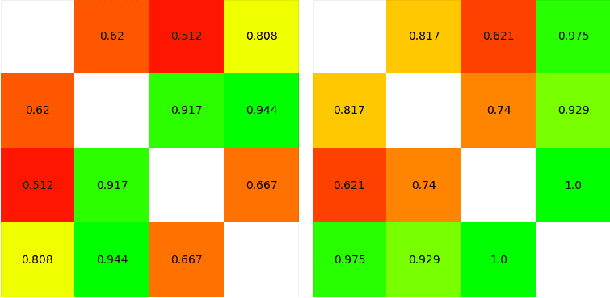
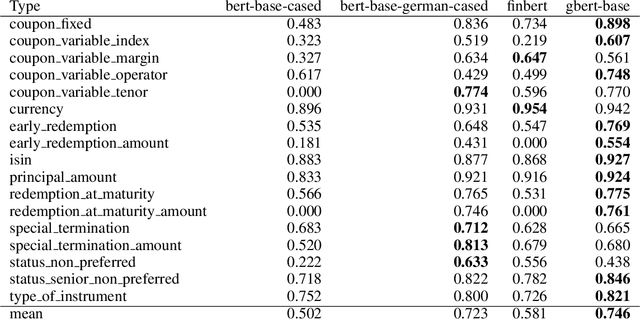
As part of its digitization initiative, the German Central Bank (Deutsche Bundesbank) wants to examine the extent to which natural Language Processing (NLP) can be used to make independent decisions upon the eligibility criteria of securities prospectuses. Every month, the Directorate General Markets at the German Central Bank receives hundreds of scanned prospectuses in PDF format, which must be manually processed to decide upon their eligibility. We found that this tedious and time-consuming process can be (semi-)automated by employing modern NLP model architectures, which learn the linguistic feature representation in text to identify the present eligible and ineligible criteria. The proposed Decision Support System provides decisions of document-level eligibility criteria accompanied by human-understandable explanations of the decisions. The aim of this project is to model the described use case and to evaluate the extent to which current research results from the field of NLP can be applied to this problem. After creating a heterogeneous domain-specific dataset containing annotations of eligible and non-eligible mentions of relevant criteria, we were able to successfully build, train and deploy a semi-automatic decider model. This model is based on transformer-based language models and decision trees, which integrate the established rule-based parts of the decision processes. Results suggest that it is possible to efficiently model the problem and automate decision making to more than 90% for many of the considered eligibility criteria.