 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Differentiation: Theory and Practice
Jul 13, 2022We present the classical coordinate-free formalism for forward and backward mode ad in the real and complex setting. We show how to formally derive the forward and backward formulae for a number of matrix functions starting from basic principles.
Geometric Optimisation on Manifolds with Applications to Deep Learning
Mar 09, 2022
We design and implement a Python library to help the non-expert using all these powerful tools in a way that is efficient, extensible, and simple to incorporate into the workflow of the data scientist, practitioner, and applied researcher. The algorithms implemented in this library have been designed with usability and GPU efficiency in mind, and they can be added to any PyTorch model with just one extra line of code. We showcase the effectiveness of these tools on an application of optimisation on manifolds in the setting of time series analysis. In this setting, orthogonal and unitary optimisation is used to constraint and regularise recurrent models and avoid vanishing and exploding gradient problems. The algorithms designed for GeoTorch allow us to achieve state of the art results in the standard tests for this family of models. We use tools from comparison geometry to give bounds on quantities that are of interest in optimisation problems. In particular, we build on the work of (Kaul 1976) to give explicit bounds on the norm of the second derivative of the Riemannian exponential.
Adaptive and Momentum Methods on Manifolds Through Trivializations
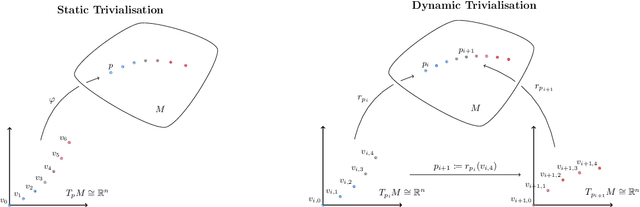
Oct 09, 2020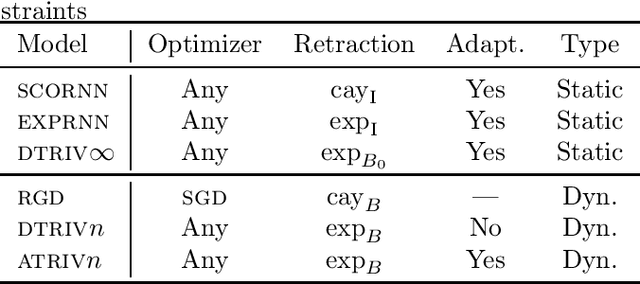


Adaptive methods do not have a direct generalization to manifolds as the adaptive term is not invariant. Momentum methods on manifolds suffer from efficiency problems stemming from the curvature of the manifold. We introduce a framework to generalize adaptive and momentum methods to arbitrary manifolds by noting that for every differentiable manifold, there exists a radially convex open set that covers almost all the manifold. Being radially convex, this set is diffeomorphic to $\mathbb{R}^n$. This gives a natural generalization of any adaptive and momentum-based algorithm to a set that covers almost all the manifold in an arbitrary manifolds. We also show how to extend these methods to the context of gradient descent methods with a retraction. For its implementation, we bring an approximation to the exponential of matrices that needs just of 5 matrix multiplications, making it particularly efficient on GPUs. In practice, we see that this family of algorithms closes the numerical gap created by an incorrect use of momentum and adaptive methods on manifolds. At the same time, we see that the most efficient algorithm of this family is given by simply pulling back the problem to the tangent space at the initial point via the exponential map.
Curvature-Dependant Global Convergence Rates for Optimization on Manifolds of Bounded Geometry
Aug 06, 2020We give curvature-dependant convergence rates for the optimization of weakly convex functions defined on a manifold of 1-bounded geometry via Riemannian gradient descent and via the dynamic trivialization algorithm. In order to do this, we give a tighter bound on the norm of the Hessian of the Riemannian exponential than the previously known. We compute these bounds explicitly for some manifolds commonly used in the optimization literature such as the special orthogonal group and the real Grassmannian. Along the way, we present self-contained proofs of fully general bounds on the norm of the differential of the exponential map and certain cosine inequalities on manifolds, which are commonly used in optimization on manifolds.
Trivializations for Gradient-Based Optimization on Manifolds
Oct 24, 2019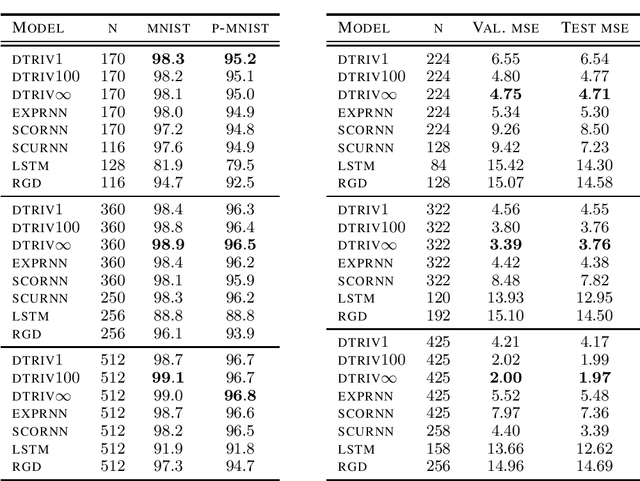
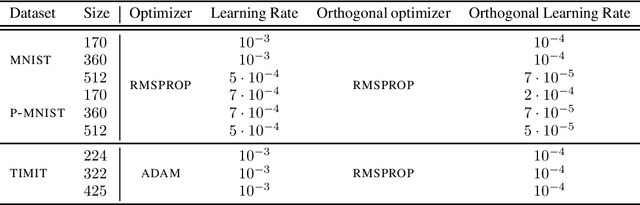
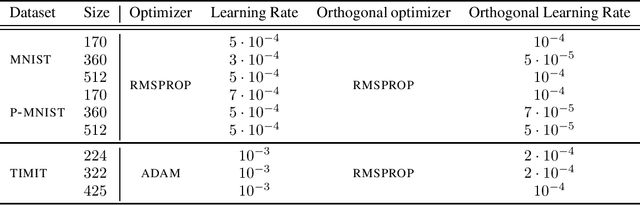
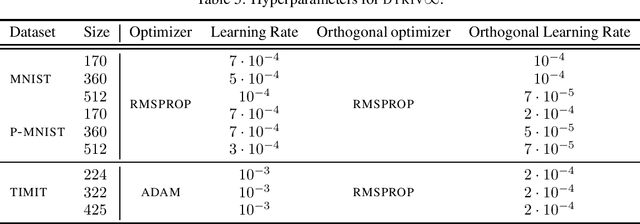
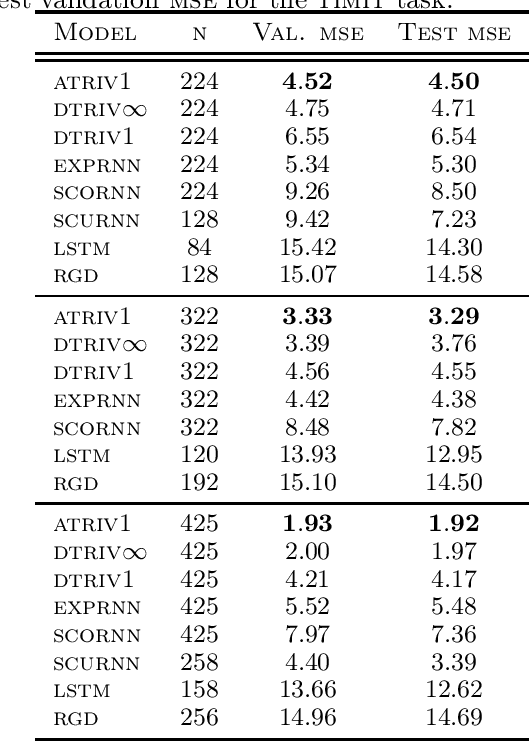
We introduce a framework to study the transformation of problems with manifold constraints into unconstrained problems through parametrizations in terms of a Euclidean space. We call these parametrizations "trivializations". We prove conditions under which a trivialization is sound in the context of gradient-based optimization and we show how two large families of trivializations have overall favorable properties, but also suffer from a performance issue. We then introduce "dynamic trivializations", which solve this problem, and we show how these form a family of optimization methods that lie between trivializations and Riemannian gradient descent, and combine the benefits of both of them. We then show how to implement these two families of trivializations in practice for different matrix manifolds. To this end, we prove a formula for the gradient of the exponential of matrices, which can be of practical interest on its own. Finally, we show how dynamic trivializations improve the performance of existing methods on standard tasks designed to test long-term memory within neural networks.
Cheap Orthogonal Constraints in Neural Networks: A Simple Parametrization of the Orthogonal and Unitary Group
Jan 25, 2019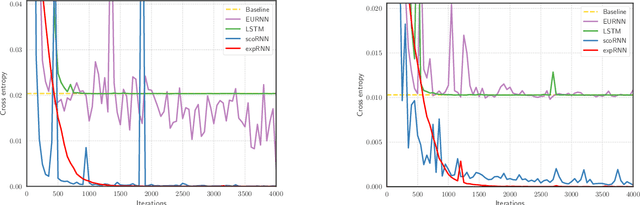

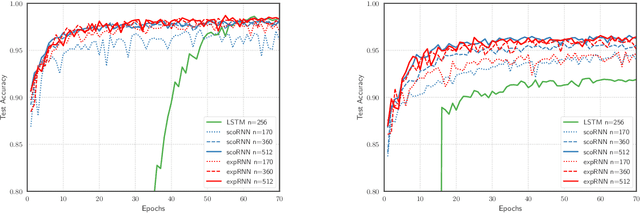
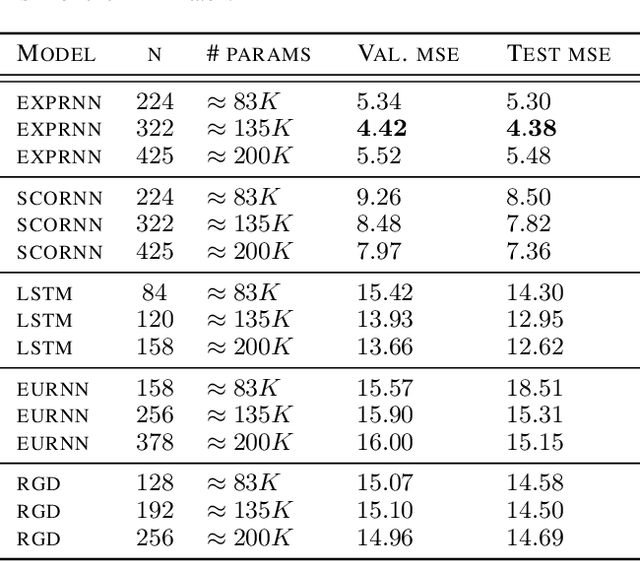
We introduce a novel approach to perform first-order optimization with orthogonal and unitary constraints. This approach is based on a parametrization stemming from Lie group theory through the exponential map. The parametrization transforms the constrained optimization problem into an unconstrained one over a Euclidean space, for which common first-order optimization methods can be used. The theoretical results presented are general enough to cover the special orthogonal group, the unitary group and, in general, any connected compact Lie group. We discuss how this and other parametrizations can be computed efficiently through an implementation trick, making numerically complex parametrizations usable at a negligible runtime cost in neural networks. In particular, we apply our results to RNNs with orthogonal recurrent weights, yielding a new architecture called expRNN. We demonstrate how our method constitutes a more robust approach to optimization with orthogonal constraints, showing faster, accurate, and more stable convergence in several tasks designed to test RNNs.