 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindTheStep-AsyncPSGD: Adaptive Asynchronous Parallel Stochastic Gradient Descent
Nov 08, 2019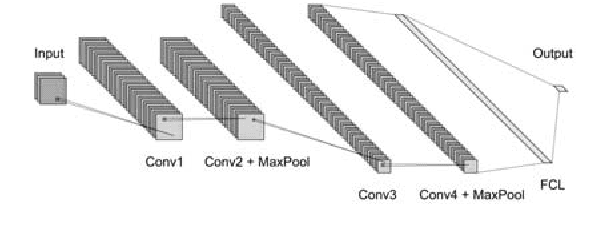
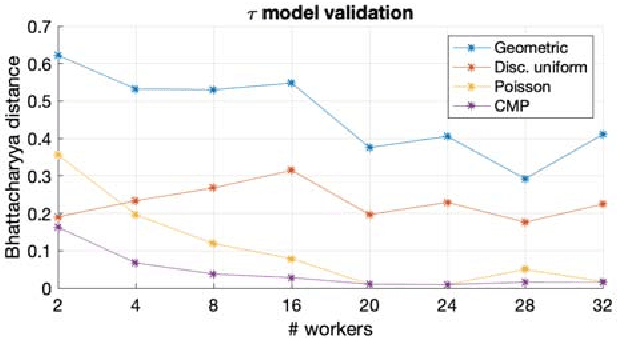
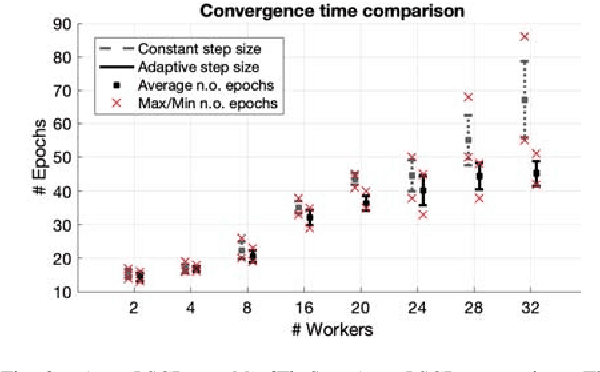
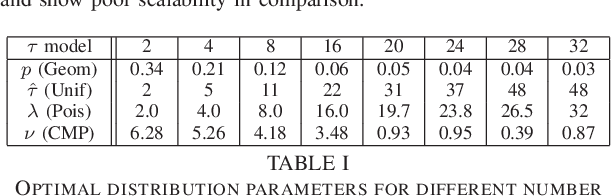
Stochastic Gradient Descent (SGD) is very useful in optimization problems with high-dimensional non-convex target functions, and hence constitutes an important component of several Machine Learning and Data Analytics methods. Recently there have been significant works on understanding the parallelism inherent to SGD, and its convergence properties. Asynchronous, parallel SGD (AsyncPSGD) has received particular attention, due to observed performance benefits. On the other hand, asynchrony implies inherent challenges in understanding the execution of the algorithm and its convergence, stemming from the fact that the contribution of a thread might be based on an old (stale) view of the state. In this work we aim to deepen the understanding of AsyncPSGD in order to increase the statistical efficiency in the presence of stale gradients. We propose new models for capturing the nature of the staleness distribution in a practical setting. Using the proposed models, we derive a staleness-adaptive SGD framework, MindTheStep-AsyncPSGD, for adapting the step size in an online-fashion, which provably reduces the negative impact of asynchrony. Moreover, we provide general convergence time bounds for a wide class of staleness-adaptive step size strategies for convex target functions. We also provide a detailed empirical study, showing how our approach implies faster convergence for deep learning applications.
Lisco: A Continuous Approach in LiDAR Point-cloud Clustering
Nov 06, 2017



The light detection and ranging (LiDAR) technology allows to sense surrounding objects with fine-grained resolution in a large areas. Their data (aka point clouds), generated continuously at very high rates, can provide information to support automated functionality in cyberphysical systems. Clustering of point clouds is a key problem to extract this type of information. Methods for solving the problem in a continuous fashion can facilitate improved processing in e.g. fog architectures, allowing continuous, streaming processing of data close to the sources. We propose Lisco, a single-pass continuous Euclidean-distance-based clustering of LiDAR point clouds, that maximizes the granularity of the data processing pipeline. Besides its algorithmic analysis, we provide a thorough experimental evaluation and highlight its up to 3x improvements and its scalability benefits compared to the baseline, using both real-world datasets as well as synthetic ones to fully explore the worst-cases.