 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaiREO: User Group Fairness for Equality of Opportunity in Course Recommendation
Sep 13, 2021

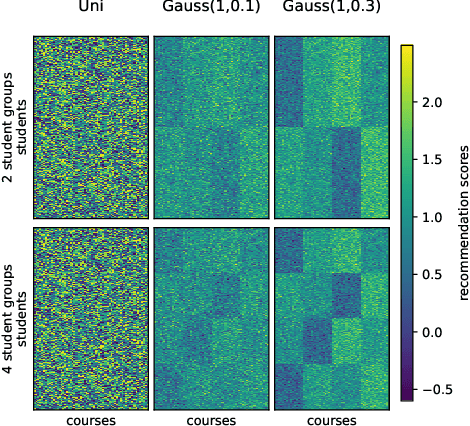

Course selection is challenging for students in higher educational institutions. Existing course recommendation systems make relevant suggestions to the students and help them in exploring the available courses. The recommended courses can influence students' choice of degree program, future employment, and even their socioeconomic status. This paper focuses on identifying and alleviating biases that might be present in a course recommender system. We strive to promote balanced opportunities with our suggestions to all groups of students. At the same time, we need to make recommendations of good quality to all protected groups. We formulate our approach as a multi-objective optimization problem and study the trade-offs between equal opportunity and quality. We evaluate our methods using both real-world and synthetic datasets. The results indicate that we can considerably improve fairness regarding equality of opportunity, but we will introduce some quality loss. Out of the four methods we tested, GHC-Inc and GHC-Tabu are the best performing ones with different advantageous characteristics.
Position-based Hash Embeddings For Scaling Graph Neural Networks
Sep 09, 2021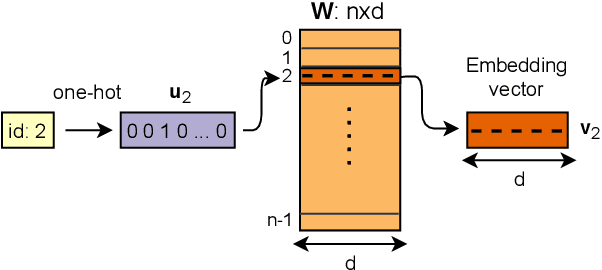

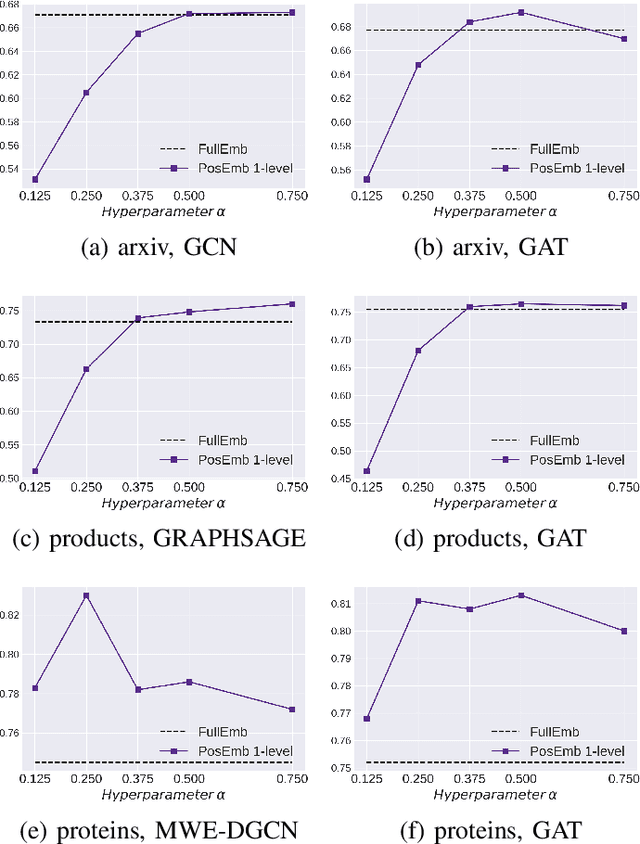

Graph Neural Networks (GNNs) bring the power of deep representation learning to graph and relational data and achieve state-of-the-art performance in many applications. GNNs compute node representations by taking into account the topology of the node's ego-network and the features of the ego-network's nodes. When the nodes do not have high-quality features, GNNs learn an embedding layer to compute node embeddings and use them as input features. However, the size of the embedding layer is linear to the product of the number of nodes in the graph and the dimensionality of the embedding and does not scale to big data and graphs with hundreds of millions of nodes. To reduce the memory associated with this embedding layer, hashing-based approaches, commonly used in applications like NLP and recommender systems, can potentially be used. However, a direct application of these ideas fails to exploit the fact that in many real-world graphs, nodes that are topologically close will tend to be related to each other (homophily) and as such their representations will be similar. In this work, we present approaches that take advantage of the nodes' position in the graph to dramatically reduce the memory required, with minimal if any degradation in the quality of the resulting GNN model. Our approaches decompose a node's embedding into two components: a position-specific component and a node-specific component. The position-specific component models homophily and the node-specific component models the node-to-node variation. Extensive experiments using different datasets and GNN models show that our methods are able to reduce the memory requirements by 88% to 97% while achieving, in nearly all cases, better classification accuracy than other competing approaches, including the full embeddings.
LLFR: A Lanczos-Based Latent Factor Recommender for Big Data Scenarios
Jun 14, 2016The purpose if this master's thesis is to study and develop a new algorithmic framework for Collaborative Filtering to produce recommendations in the top-N recommendation problem. Thus, we propose Lanczos Latent Factor Recommender (LLFR); a novel "big data friendly" collaborative filtering algorithm for top-N recommendation. Using a computationally efficient Lanczos-based procedure, LLFR builds a low dimensional item similarity model, that can be readily exploited to produce personalized ranking vectors over the item space. A number of experiments on real datasets indicate that LLFR outperforms other state-of-the-art top-N recommendation methods from a computational as well as a qualitative perspective. Our experimental results also show that its relative performance gains, compared to competing methods, increase as the data get sparser, as in the Cold Start Problem. More specifically, this is true both when the sparsity is generalized - as in the New Community Problem, a very common problem faced by real recommender systems in their beginning stages, when there is not sufficient number of ratings for the collaborative filtering algorithms to uncover similarities between items or users - and in the very interesting case where the sparsity is localized in a small fraction of the dataset - as in the New Users Problem, where new users are introduced to the system, they have not rated many items and thus, the CF algorithm can not make reliable personalized recommendations yet.