 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent-like relaxation is equivalent to Glauber dynamics in discrete optimization and inference problems
Sep 11, 2023Is Stochastic Gradient Descent (SGD) substantially different from Glauber dynamics? This is a fundamental question at the time of understanding the most used training algorithm in the field of Machine Learning, but it received no answer until now. Here we show that in discrete optimization and inference problems, the dynamics of an SGD-like algorithm resemble very closely that of Metropolis Monte Carlo with a properly chosen temperature, which depends on the mini-batch size. This quantitative matching holds both at equilibrium and in the out-of-equilibrium regime, despite the two algorithms having fundamental differences (e.g.\ SGD does not satisfy detailed balance). Such equivalence allows us to use results about performances and limits of Monte Carlo algorithms to optimize the mini-batch size in the SGD-like algorithm and make it efficient at recovering the signal in hard inference problems.
Cracking nuts with a sledgehammer: when modern graph neural networks do worse than classical greedy algorithms
Jun 27, 2022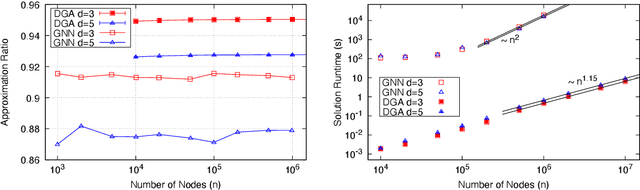
The recent work ``Combinatorial Optimization with Physics-Inspired Graph Neural Networks'' [Nat Mach Intell 4 (2022) 367] introduces a physics-inspired unsupervised Graph Neural Network (GNN) to solve combinatorial optimization problems on sparse graphs. To test the performances of these GNNs, the authors of the work show numerical results for two fundamental problems: maximum cut and maximum independent set (MIS). They conclude that "the graph neural network optimizer performs on par or outperforms existing solvers, with the ability to scale beyond the state of the art to problems with millions of variables." In this comment, we show that a simple greedy algorithm, running in almost linear time, can find solutions for the MIS problem of much better quality than the GNN. The greedy algorithm is faster by a factor of $10^4$ with respect to the GNN for problems with a million variables. We do not see any good reason for solving the MIS with these GNN, as well as for using a sledgehammer to crack nuts. In general, many claims of superiority of neural networks in solving combinatorial problems are at risk of being not solid enough, since we lack standard benchmarks based on really hard problems. We propose one of such hard benchmarks, and we hope to see future neural network optimizers tested on these problems before any claim of superiority is made.