 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuleKit 2: Faster and simpler rule learning
Apr 29, 2025Rules offer an invaluable combination of predictive and descriptive capabilities. Our package for rule-based data analysis, RuleKit, has proven its effectiveness in classification, regression, and survival problems. Here we present its second version. New algorithms and optimized implementations of those previously included, significantly improved the computational performance of our suite, reducing the analysis time of some data sets by two orders of magnitude. The usability of RuleKit 2 is provided by two new components: Python package and browser application with a graphical user interface. The former complies with scikit-learn, the most popular data mining library for Python, allowing RuleKit 2 to be straightforwardly integrated into existing data analysis pipelines. RuleKit 2 is available at GitHub under GNU AGPL 3 license (https://github.com/adaa-polsl/RuleKit)
Separate and conquer heuristic allows robust mining of contrast sets from various types of data
Apr 01, 2022



Identifying differences between groups is one of the most important knowledge discovery problems. The procedure, also known as contrast sets mining, is applied in a wide range of areas like medicine, industry, or economics. In the paper we present RuleKit-CS, an algorithm for contrast set mining based on a sequential covering - a well established heuristic for decision rule induction. Multiple passes accompanied with an attribute penalization scheme allow generating contrast sets describing same examples with different attributes, unlike the standard sequential covering. The ability to identify contrast sets in regression and survival data sets, the feature not provided by the existing algorithms, further extends the usability of RuleKit-CS. Experiments on wide range of data sets confirmed RuleKit-CS to be a useful tool for discovering differences between defined groups. The algorithm is a part of the RuleKit suite available at GitHub under GNU AGPL 3 licence (https://github.com/adaa-polsl/RuleKit). Keywords: Contrast sets, Sequential covering, Rule induction, Regression, Survival, Knowledge discovery
SCARI: Separate and Conquer Algorithm for Action Rules and Recommendations Induction
Jun 09, 2021



This article describes an action rule induction algorithm based on a sequential covering approach. Two variants of the algorithm are presented. The algorithm allows the action rule induction from a source and a target decision class point of view. The application of rule quality measures enables the induction of action rules that meet various quality criteria. The article also presents a method for recommendation induction. The recommendations indicate the actions to be taken to move a given test example, representing the source class, to the target one. The recommendation method is based on a set of induced action rules. The experimental part of the article presents the results of the algorithm operation on sixteen data sets. As a result of the conducted research the Ac-Rules package was made available.
Classification supporting COVID-19 diagnostics based on patient survey data
Nov 24, 2020
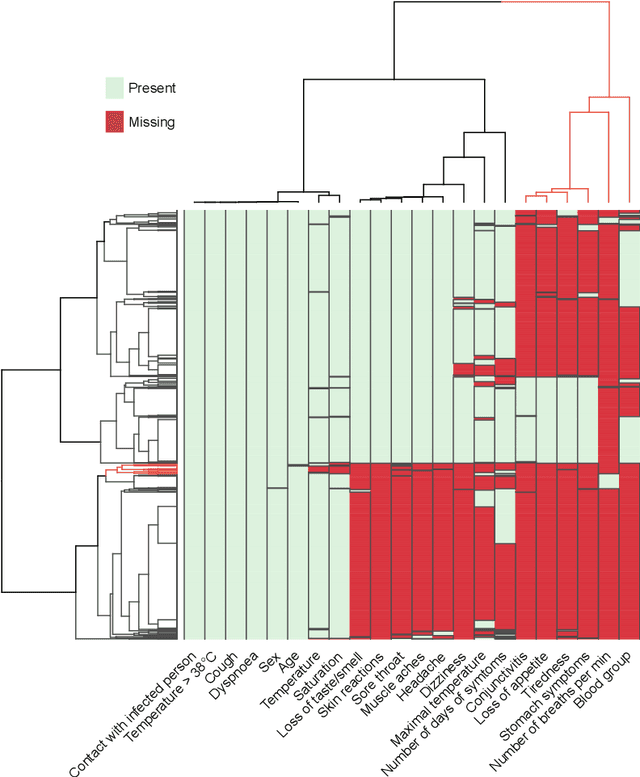

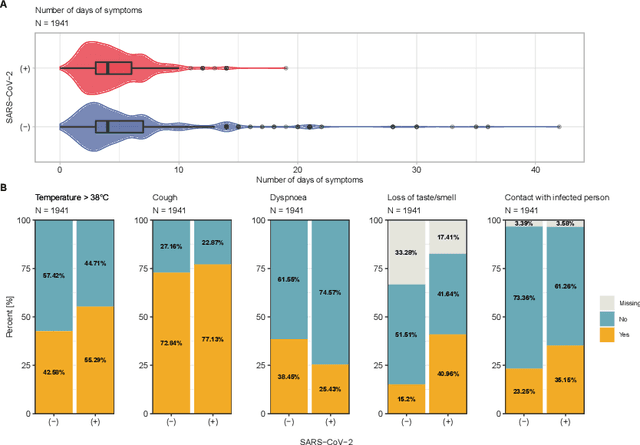
Distinguishing COVID-19 from other flu-like illnesses can be difficult due to ambiguous symptoms and still an initial experience of doctors. Whereas, it is crucial to filter out those sick patients who do not need to be tested for SARS-CoV-2 infection, especially in the event of the overwhelming increase in disease. As a part of the presented research, logistic regression and XGBoost classifiers, that allow for effective screening of patients for COVID-19, were generated. Each of the methods was tuned to achieve an assumed acceptable threshold of negative predictive values during classification. Additionally, an explanation of the obtained classification models was presented. The explanation enables the users to understand what was the basis of the decision made by the model. The obtained classification models provided the basis for the DECODE service (decode.polsl.pl), which can serve as support in screening patients with COVID-19 disease. Moreover, the data set constituting the basis for the analyses performed is made available to the research community. This data set consisting of more than 3,000 examples is based on questionnaires collected at a hospital in Poland.
Gradient Boosting Application in Forecasting of Performance Indicators Values for Measuring the Efficiency of Promotions in FMCG Retail
May 30, 2020



In the paper, a problem of forecasting promotion efficiency is raised. The authors propose a new approach, using the gradient boosting method for this task. Six performance indicators are introduced to capture the promotion effect. For each of them, within predefined groups of products, a model was trained. A description of using these models for forecasting and optimising promotion efficiency is provided. Data preparation and hyperparameters tuning processes are also described. The experiments were performed for three groups of products from a large grocery company.
RuleKit: A Comprehensive Suite for Rule-Based Learning
Aug 02, 2019


Rule-based models are often used for data analysis as they combine interpretability with predictive power. We present RuleKit, a versatile tool for rule learning. Based on a sequential covering induction algorithm, it is suitable for classification, regression, and survival problems. The presence of a user-guided induction facilitates verifying hypotheses concerning data dependencies which are expected or of interest. The powerful and flexible experimental environment allows straightforward investigation of different induction schemes. The analysis can be performed in batch mode, through RapidMiner plug-in, or R package. A documented Java API is also provided for convenience. The software is publicly available at GitHub under GNU AGPL-3.0 license.
GuideR: a guided separate-and-conquer rule learning in classification, regression, and survival settings
Jun 05, 2018



This article presents GuideR, a user-guided rule induction algorithm, which overcomes the largest limitation of the existing methods-the lack of the possibility to introduce user's preferences or domain knowledge to the rule learning process. Automatic selection of attributes and attribute ranges often leads to the situation in which resulting rules do not contain interesting information. We propose an induction algorithm which takes into account user's requirements. Our method uses the sequential covering approach and is suitable for classification, regression, and survival analysis problems. The effectiveness of the algorithm in all these tasks has been verified experimentally, confirming guided rule induction to be a powerful data analysis tool.