 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian processes based data augmentation and expected signature for time series classification
Oct 16, 2023



The signature is a fundamental object that describes paths (that is, continuous functions from an interval to a Euclidean space). Likewise, the expected signature provides a statistical description of the law of stochastic processes. We propose a feature extraction model for time series built upon the expected signature. This is computed through a Gaussian processes based data augmentation. One of the main features is that an optimal feature extraction is learnt through the supervised task that uses the model.
Curious Explorer: a provable exploration strategy in Policy Learning
Jun 29, 2021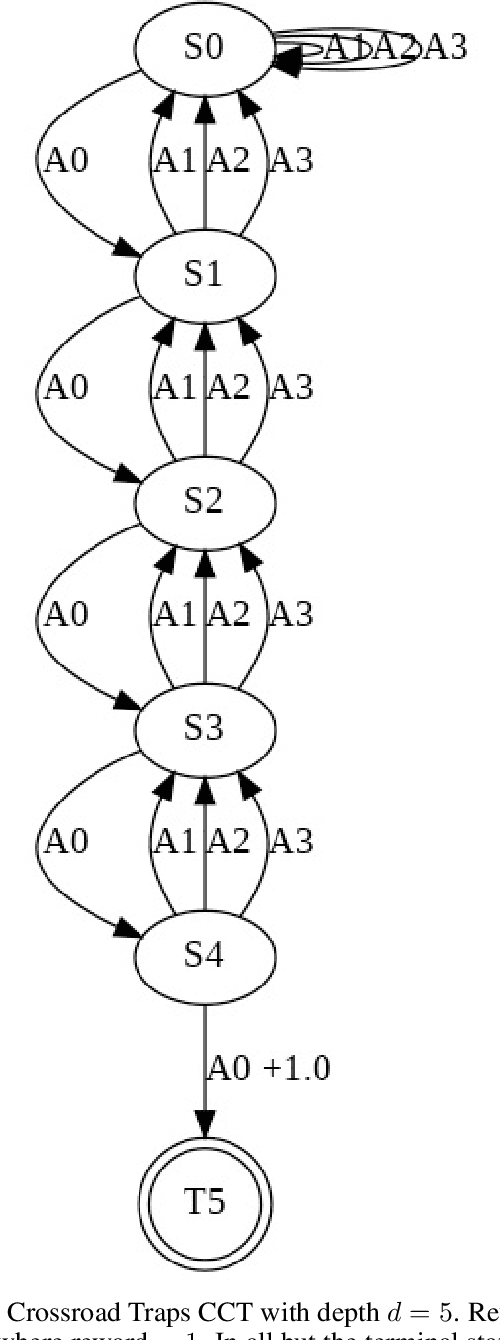
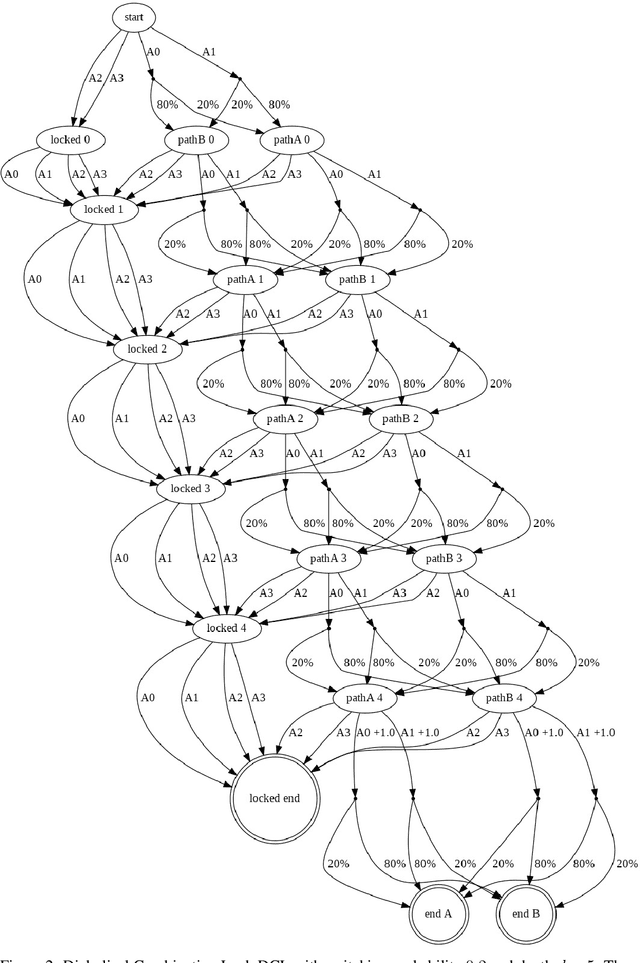
Having access to an exploring restart distribution (the so-called wide coverage assumption) is critical with policy gradient methods. This is due to the fact that, while the objective function is insensitive to updates in unlikely states, the agent may still need improvements in those states in order to reach a nearly optimal payoff. For this reason, wide coverage is used in some form when analyzing theoretical properties of practical policy gradient methods. However, this assumption can be unfeasible in certain environments, for instance when learning is online, or when restarts are possible only from a fixed initial state. In these cases, classical policy gradient algorithms can have very poor convergence properties and sample efficiency. In this paper, we develop Curious Explorer, a novel and simple iterative state space exploration strategy that can be used with any starting distribution $\rho$. Curious Explorer starts from $\rho$, then using intrinsic rewards assigned to the set of poorly visited states produces a sequence of policies, each one more exploratory than the previous one in an informed way, and finally outputs a restart model $\mu$ based on the state visitation distribution of the exploratory policies. Curious Explorer is provable, in the sense that we provide theoretical upper bounds on how often an optimal policy visits poorly visited states. These bounds can be used to prove PAC convergence and sample efficiency results when a PAC optimizer is plugged in Curious Explorer. This allows to achieve global convergence and sample efficiency results without any coverage assumption for REINFORCE, and potentially for any other policy gradient method ensuring PAC convergence with wide coverage. Finally, we plug (the output of) Curious Explorer into REINFORCE and TRPO, and show empirically that it can improve performance in MDPs with challenging exploration.