 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Constrained Learning
Feb 04, 2022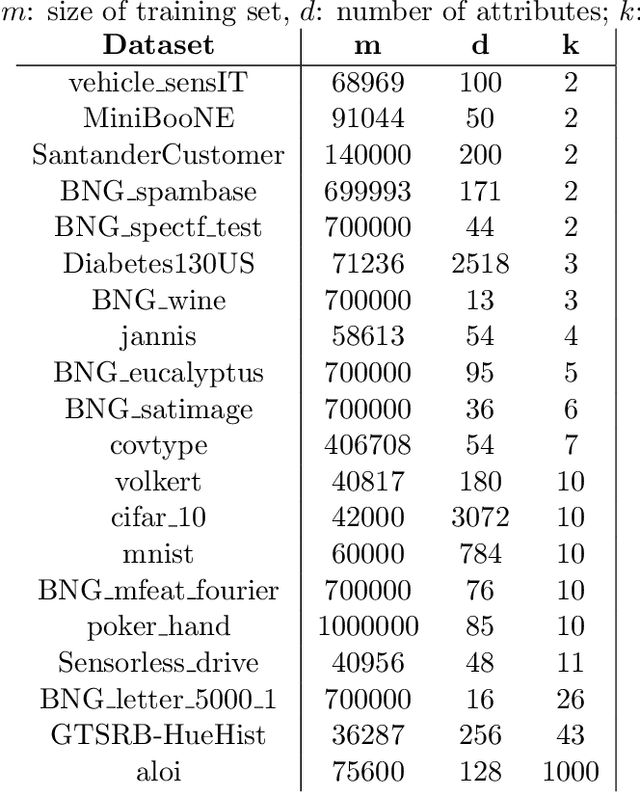
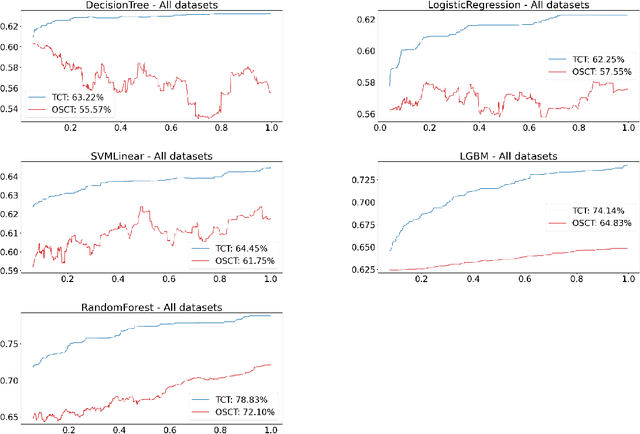
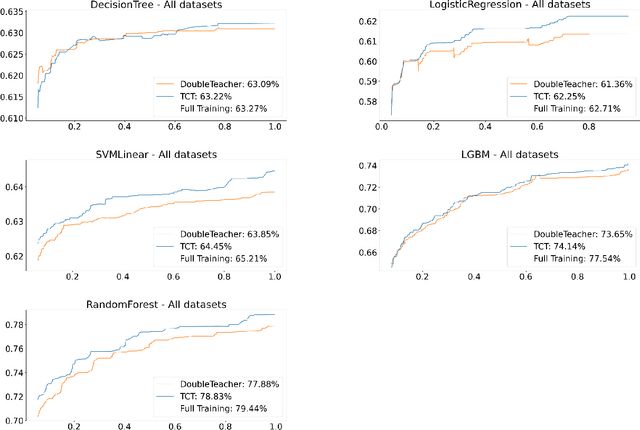
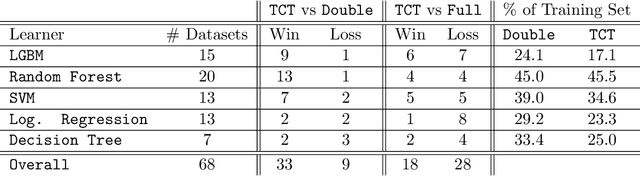
Consider a scenario in which we have a huge labeled dataset ${\cal D}$ and a limited time to train some given learner using ${\cal D}$. Since we may not be able to use the whole dataset, how should we proceed? Questions of this nature motivate the definition of the Time-Constrained Learning Task (TCL): Given a dataset ${\cal D}$ sampled from an unknown distribution $\mu$, a learner ${\cal L}$ and a time limit $T$, the goal is to obtain in at most $T$ units of time the classification model with highest possible accuracy w.r.t. to $\mu$, among those that can be built by ${\cal L}$ using the dataset ${\cal D}$. We propose TCT, an algorithm for the TCL task designed based that on principles from Machine Teaching. We present an experimental study involving 5 different Learners and 20 datasets where we show that TCT consistently outperforms two other algorithms: the first is a Teacher for black-box learners proposed in [Dasgupta et al., ICML 19] and the second is a natural adaptation of random sampling for the TCL setting. We also compare TCT with Stochastic Gradient Descent training -- our method is again consistently better. While our work is primarily practical, we also show that a stripped-down version of TCT has provable guarantees. Under reasonable assumptions, the time our algorithm takes to achieve a certain accuracy is never much bigger than the time it takes the batch teacher (which sends a single batch of examples) to achieve similar accuracy, and in some case it is almost exponentially better.
Geometry of Online Packing Linear Programs
Apr 26, 2012
We consider packing LP's with $m$ rows where all constraint coefficients are normalized to be in the unit interval. The n columns arrive in random order and the goal is to set the corresponding decision variables irrevocably when they arrive so as to obtain a feasible solution maximizing the expected reward. Previous (1 - \epsilon)-competitive algorithms require the right-hand side of the LP to be Omega((m/\epsilon^2) log (n/\epsilon)), a bound that worsens with the number of columns and rows. However, the dependence on the number of columns is not required in the single-row case and known lower bounds for the general case are also independent of n. Our goal is to understand whether the dependence on n is required in the multi-row case, making it fundamentally harder than the single-row version. We refute this by exhibiting an algorithm which is (1 - \epsilon)-competitive as long as the right-hand sides are Omega((m^2/\epsilon^2) log (m/\epsilon)). Our techniques refine previous PAC-learning based approaches which interpret the online decisions as linear classifications of the columns based on sampled dual prices. The key ingredient of our improvement comes from a non-standard covering argument together with the realization that only when the columns of the LP belong to few 1-d subspaces we can obtain small such covers; bounding the size of the cover constructed also relies on the geometry of linear classifiers. General packing LP's are handled by perturbing the input columns, which can be seen as making the learning problem more robust.