 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Bandit Algorithms for Settings with Sequentially Available Arms
Sep 30, 2021
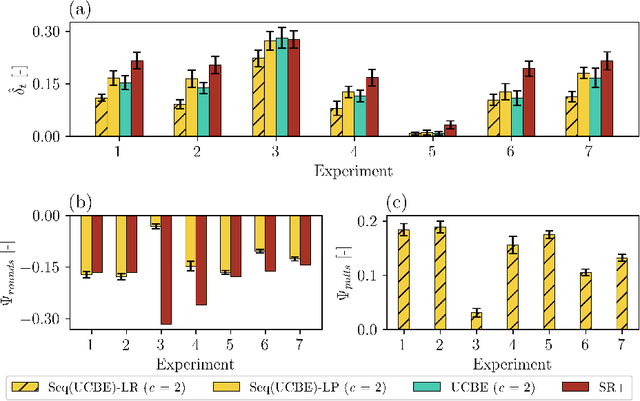
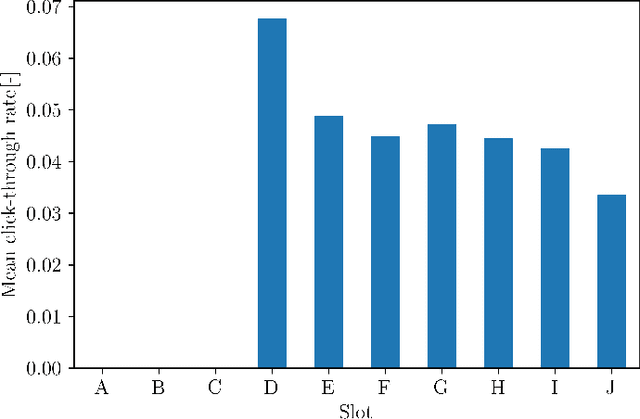
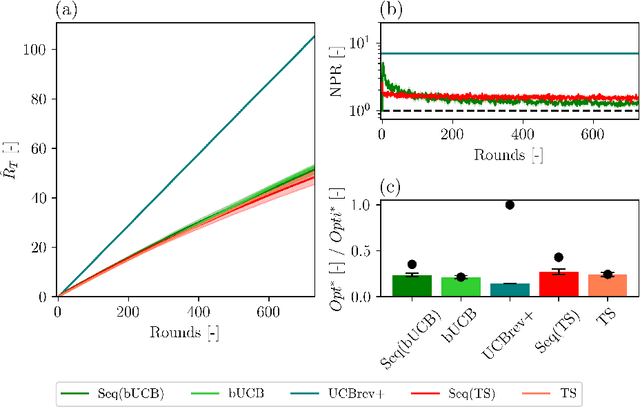
Although the classical version of the Multi-Armed Bandits (MAB) framework has been applied successfully to several practical problems, in many real-world applications, the possible actions are not presented to the learner simultaneously, such as in the Internet campaign management and environmental monitoring settings. Instead, in such applications, a set of options is presented sequentially to the learner within a time span, and this process is repeated throughout a time horizon. At each time, the learner is asked whether to select the proposed option or not. We define this scenario as the Sequential Pull/No-pull Bandit setting, and we propose a meta-algorithm, namely Sequential Pull/No-pull for MAB (Seq), to adapt any classical MAB policy to better suit this setting for both the regret minimization and best-arm identification problems. By allowing the selection of multiple arms within a round, the proposed meta-algorithm gathers more information, especially in the first rounds, characterized by a high uncertainty in the arms estimate value. At the same time, the adapted algorithms provide the same theoretical guarantees as the classical policy employed. The Seq meta-algorithm was extensively tested and compared with classical MAB policies on synthetic and real-world datasets from advertising and environmental monitoring applications, highlighting its good empirical performances.