 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Clustering Categories of Categorical Predictors in Generalized Linear Models
Oct 19, 2021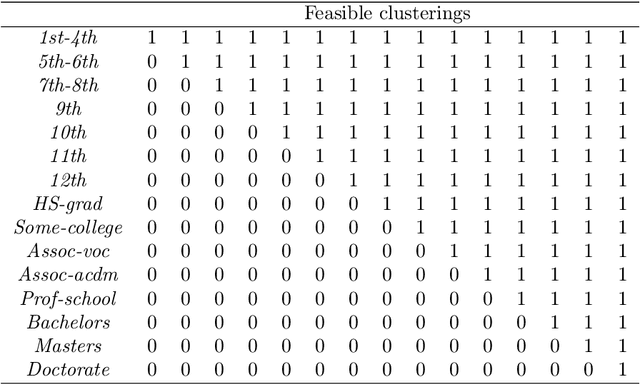

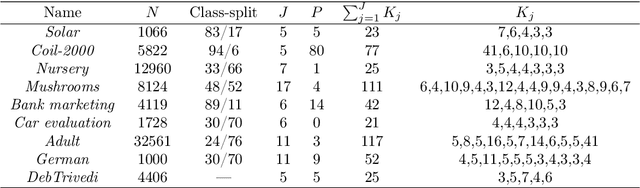
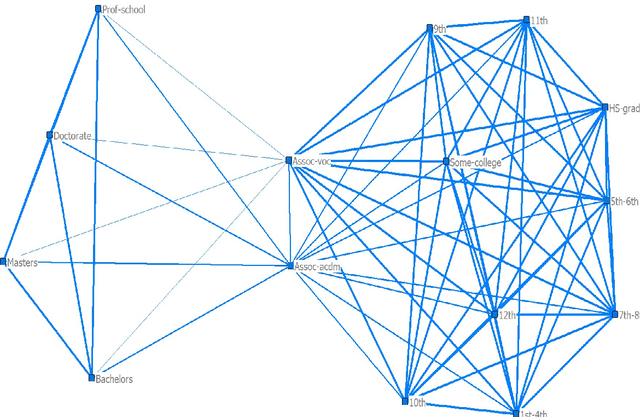
We propose a method to reduce the complexity of Generalized Linear Models in the presence of categorical predictors. The traditional one-hot encoding, where each category is represented by a dummy variable, can be wasteful, difficult to interpret, and prone to overfitting, especially when dealing with high-cardinality categorical predictors. This paper addresses these challenges by finding a reduced representation of the categorical predictors by clustering their categories. This is done through a numerical method which aims to preserve (or even, improve) accuracy, while reducing the number of coefficients to be estimated for the categorical predictors. Thanks to its design, we are able to derive a proximity measure between categories of a categorical predictor that can be easily visualized. We illustrate the performance of our approach in real-world classification and count-data datasets where we see that clustering the categorical predictors reduces complexity substantially without harming accuracy.