 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Automated Machine Learning for Credit Decisions: Enhancing Human Artificial Intelligence Collaboration in Financial Engineering
Feb 06, 2024This paper explores the integration of Explainable Automated Machine Learning (AutoML) in the realm of financial engineering, specifically focusing on its application in credit decision-making. The rapid evolution of Artificial Intelligence (AI) in finance has necessitated a balance between sophisticated algorithmic decision-making and the need for transparency in these systems. The focus is on how AutoML can streamline the development of robust machine learning models for credit scoring, while Explainable AI (XAI) methods, particularly SHapley Additive exPlanations (SHAP), provide insights into the models' decision-making processes. This study demonstrates how the combination of AutoML and XAI not only enhances the efficiency and accuracy of credit decisions but also fosters trust and collaboration between humans and AI systems. The findings underscore the potential of explainable AutoML in improving the transparency and accountability of AI-driven financial decisions, aligning with regulatory requirements and ethical considerations.
Human-Centered AI Product Prototyping with No-Code AutoML: Conceptual Framework, Potentials and Limitations
Feb 06, 2024This paper evaluates No-Code AutoML as a solution for challenges in AI product prototyping, characterized by unpredictability and inaccessibility to non-experts, and proposes a conceptual framework. This complexity of AI products hinders seamless execution and interdisciplinary collaboration crucial for human-centered AI products. Relevant to industry and innovation, it affects strategic decision-making and investment risk mitigation. Current approaches provide limited insights into the potential and feasibility of AI product ideas. Employing Design Science Research, the study identifies challenges and integrates no-code AutoML as a solution by presenting a framework for AI product prototyping with No-code AutoML. A case study confirms its potential in supporting non-experts, offering a structured approach to AI product development. The framework facilitates accessible and interpretable prototyping, benefiting academia, managers, and decision-makers. Strategic integration of no-code AutoML enhances efficiency, empowers non-experts, and informs early-stage decisions, albeit with acknowledged limitations.
Automated machine learning: AI-driven decision making in business analytics
May 21, 2022



The realization that AI-driven decision-making is indispensable in todays fast-paced and ultra-competitive marketplace has raised interest in industrial machine learning (ML) applications significantly. The current demand for analytics experts vastly exceeds the supply. One solution to this problem is to increase the user-friendliness of ML frameworks to make them more accessible for the non-expert. Automated machine learning (AutoML) is an attempt to solve the problem of expertise by providing fully automated off-the-shelf solutions for model choice and hyperparameter tuning. This paper analyzed the potential of AutoML for applications within business analytics, which could help to increase the adoption rate of ML across all industries. The H2O AutoML framework was benchmarked against a manually tuned stacked ML model on three real-world datasets to test its performance, robustness, and reliability. The manually tuned ML model could reach a performance advantage in all three case studies used in the experiment. Nevertheless, the H2O AutoML package proved to be quite potent. It is fast, easy to use, and delivers reliable results, which come close to a professionally tuned ML model. The H2O AutoML framework in its current capacity is a valuable tool to support fast prototyping with the potential to shorten development and deployment cycles. It can also bridge the existing gap between supply and demand for ML experts and is a big step towards fully automated decisions in business analytics.
Deep Learning vs. Gradient Boosting: Benchmarking state-of-the-art machine learning algorithms for credit scoring
May 21, 2022

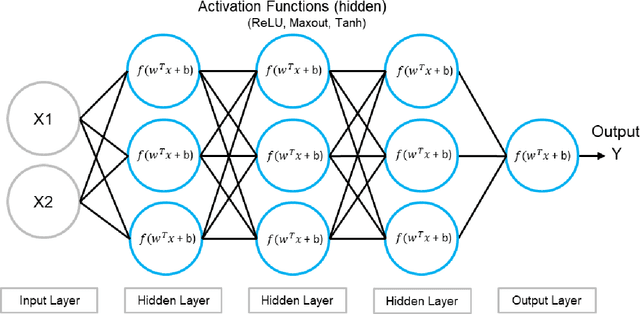
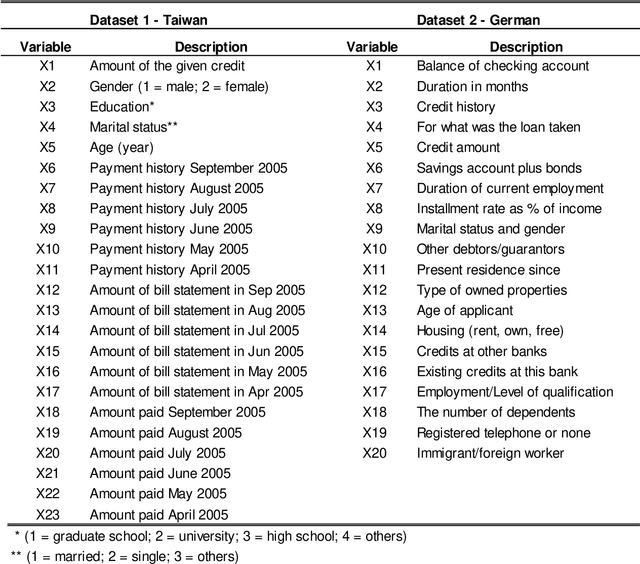
Artificial intelligence (AI) and machine learning (ML) have become vital to remain competitive for financial services companies around the globe. The two models currently competing for the pole position in credit risk management are deep learning (DL) and gradient boosting machines (GBM). This paper benchmarked those two algorithms in the context of credit scoring using three distinct datasets with different features to account for the reality that model choice/power is often dependent on the underlying characteristics of the dataset. The experiment has shown that GBM tends to be more powerful than DL and has also the advantage of speed due to lower computational requirements. This makes GBM the winner and choice for credit scoring. However, it was also shown that the outperformance of GBM is not always guaranteed and ultimately the concrete problem scenario or dataset will determine the final model choice. Overall, based on this study both algorithms can be considered state-of-the-art for binary classification tasks on structured datasets, while GBM should be the go-to solution for most problem scenarios due to easier use, significantly faster training time, and superior accuracy.