 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurfing the modeling of PoS taggers in low-resource scenarios
Feb 04, 2024



The recent trend towards the application of deep structured techniques has revealed the limits of huge models in natural language processing. This has reawakened the interest in traditional machine learning algorithms, which have proved still to be competitive in certain contexts, in particular low-resource settings. In parallel, model selection has become an essential task to boost performance at reasonable cost, even more so when we talk about processes involving domains where the training and/or computational resources are scarce. Against this backdrop, we evaluate the early estimation of learning curves as a practical mechanism for selecting the most appropriate model in scenarios characterized by the use of non-deep learners in resource-lean settings. On the basis of a formal approximation model previously evaluated under conditions of wide availability of training and validation resources, we study the reliability of such an approach in a different and much more demanding operationalenvironment. Using as case study the generation of PoS taggers for Galician, a language belonging to the Western Ibero-Romance group, the experimental results are consistent with our expectations.
* 17 papes, 5 figures
Absolute convergence and error thresholds in non-active adaptive sampling
Feb 04, 2024Non-active adaptive sampling is a way of building machine learning models from a training data base which are supposed to dynamically and automatically derive guaranteed sample size. In this context and regardless of the strategy used in both scheduling and generating of weak predictors, a proposal for calculating absolute convergence and error thresholds is described. We not only make it possible to establish when the quality of the model no longer increases, but also supplies a proximity condition to estimate in absolute terms how close it is to achieving such a goal, thus supporting decision making for fine-tuning learning parameters in model selection. The technique proves its correctness and completeness with respect to our working hypotheses, in addition to strengthening the robustness of the sampling scheme. Tests meet our expectations and illustrate the proposal in the domain of natural language processing, taking the generation of part-of-speech taggers as case study.
* 27 pages, 10 figures
Adaptive scheduling for adaptive sampling in POS taggers construction
Feb 04, 2024We introduce an adaptive scheduling for adaptive sampling as a novel way of machine learning in the construction of part-of-speech taggers. The goal is to speed up the training on large data sets, without significant loss of performance with regard to an optimal configuration. In contrast to previous methods using a random, fixed or regularly rising spacing between the instances, ours analyzes the shape of the learning curve geometrically in conjunction with a functional model to increase or decrease it at any time. The algorithm proves to be formally correct regarding our working hypotheses. Namely, given a case, the following one is the nearest ensuring a net gain of learning ability from the former, it being possible to modulate the level of requirement for this condition. We also improve the robustness of sampling by paying greater attention to those regions of the training data base subject to a temporary inflation in performance, thus preventing the learning from stopping prematurely. The proposal has been evaluated on the basis of its reliability to identify the convergence of models, corroborating our expectations. While a concrete halting condition is used for testing, users can choose any condition whatsoever to suit their own specific needs.
* 23 pager, 10 figures
Modeling of learning curves with applications to pos tagging
Feb 04, 2024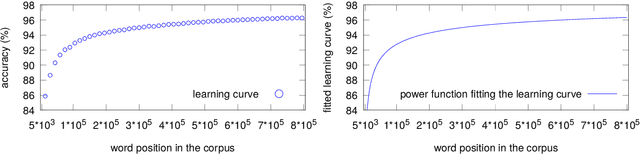
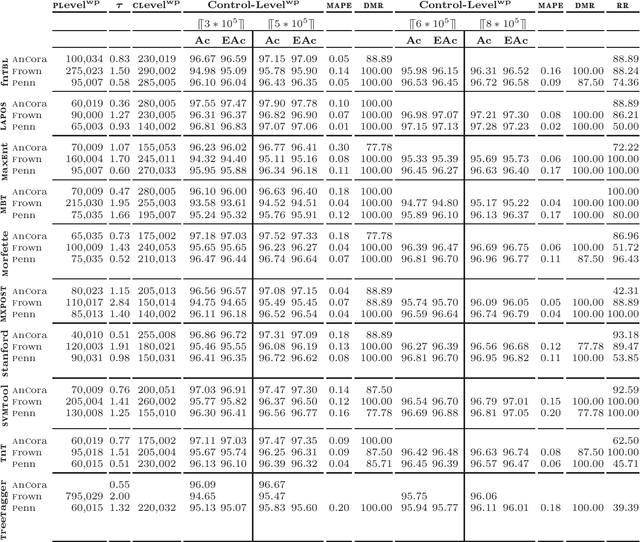
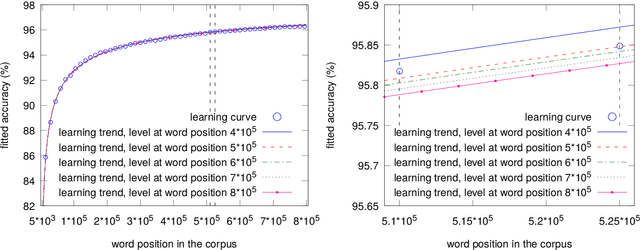
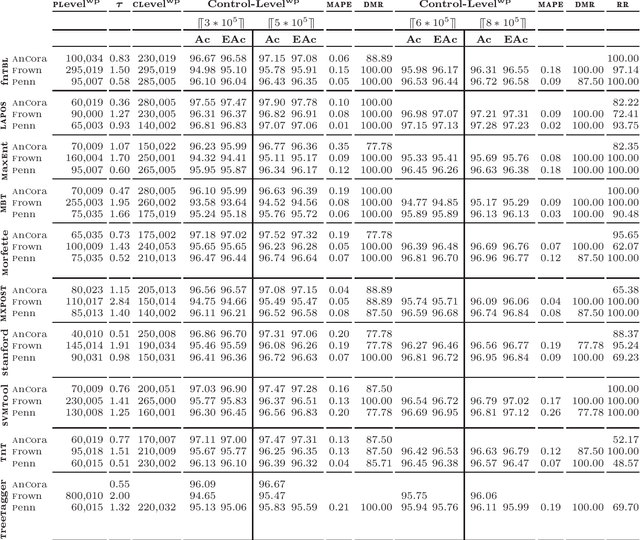
An algorithm to estimate the evolution of learning curves on the whole of a training data base, based on the results obtained from a portion and using a functional strategy, is introduced. We approximate iteratively the sought value at the desired time, independently of the learning technique used and once a point in the process, called prediction level, has been passed. The proposal proves to be formally correct with respect to our working hypotheses and includes a reliable proximity condition. This allows the user to fix a convergence threshold with respect to the accuracy finally achievable, which extends the concept of stopping criterion and seems to be effective even in the presence of distorting observations. Our aim is to evaluate the training effort, supporting decision making in order to reduce the need for both human and computational resources during the learning process. The proposal is of interest in at least three operational procedures. The first is the anticipation of accuracy gain, with the purpose of measuring how much work is needed to achieve a certain degree of performance. The second relates the comparison of efficiency between systems at training time, with the objective of completing this task only for the one that best suits our requirements. The prediction of accuracy is also a valuable item of information for customizing systems, since we can estimate in advance the impact of settings on both the performance and the development costs. Using the generation of part-of-speech taggers as an example application, the experimental results are consistent with our expectations.
* 30 pages, 11 figures
Early stopping by correlating online indicators in neural networks
Feb 04, 2024



In order to minimize the generalization error in neural networks, a novel technique to identify overfitting phenomena when training the learner is formally introduced. This enables support of a reliable and trustworthy early stopping condition, thus improving the predictive power of that type of modeling. Our proposal exploits the correlation over time in a collection of online indicators, namely characteristic functions for indicating if a set of hypotheses are met, associated with a range of independent stopping conditions built from a canary judgment to evaluate the presence of overfitting. That way, we provide a formal basis for decision making in terms of interrupting the learning process. As opposed to previous approaches focused on a single criterion, we take advantage of subsidiarities between independent assessments, thus seeking both a wider operating range and greater diagnostic reliability. With a view to illustrating the effectiveness of the halting condition described, we choose to work in the sphere of natural language processing, an operational continuum increasingly based on machine learning. As a case study, we focus on parser generation, one of the most demanding and complex tasks in the domain. The selection of cross-validation as a canary function enables an actual comparison with the most representative early stopping conditions based on overfitting identification, pointing to a promising start toward an optimal bias and variance control.
* 26 pages, 6 figures