 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound event detection with audio-text models and heterogeneous temporal annotations
Aug 28, 2025Recent advances in generating synthetic captions based on audio and related metadata allow using the information contained in natural language as input for other audio tasks. In this paper, we propose a novel method to guide a sound event detection system with free-form text. We use machine-generated captions as complementary information to the strong labels for training, and evaluate the systems using different types of textual inputs. In addition, we study a scenario where only part of the training data has strong labels, and the rest of it only has temporally weak labels. Our findings show that synthetic captions improve the performance in both cases compared to the CRNN architecture typically used for sound event detection. On a dataset of 50 highly unbalanced classes, the PSDS-1 score increases from 0.223 to 0.277 when trained with strong labels, and from 0.166 to 0.218 when half of the training data has only weak labels.
DCASE 2024 Task 4: Sound Event Detection with Heterogeneous Data and Missing Labels
Jun 12, 2024


The Detection and Classification of Acoustic Scenes and Events Challenge Task 4 aims to advance sound event detection (SED) systems in domestic environments by leveraging training data with different supervision uncertainty. Participants are challenged in exploring how to best use training data from different domains and with varying annotation granularity (strong/weak temporal resolution, soft/hard labels), to obtain a robust SED system that can generalize across different scenarios. Crucially, annotation across available training datasets can be inconsistent and hence sound labels of one dataset may be present but not annotated in the other one and vice-versa. As such, systems will have to cope with potentially missing target labels during training. Moreover, as an additional novelty, systems will also be evaluated on labels with different granularity in order to assess their robustness for different applications. To lower the entry barrier for participants, we developed an updated baseline system with several caveats to address these aforementioned problems. Results with our baseline system indicate that this research direction is promising and is possible to obtain a stronger SED system by using diverse domain training data with missing labels compared to training a SED system for each domain separately.
Evaluating Classification Systems Against Soft Labels with Fuzzy Precision and Recall
Sep 25, 2023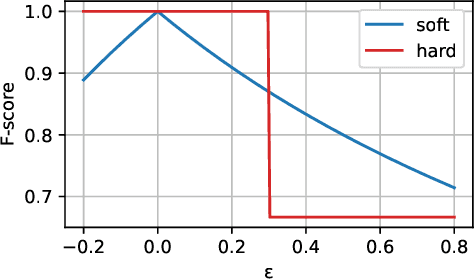
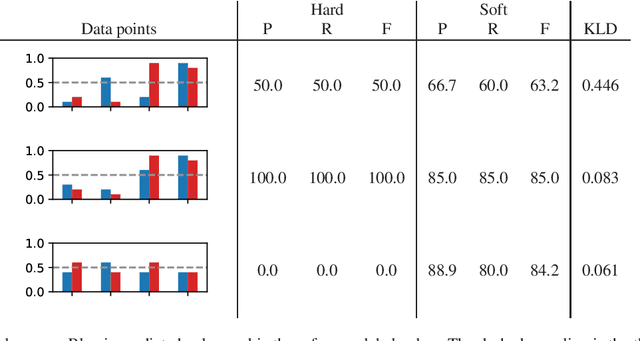
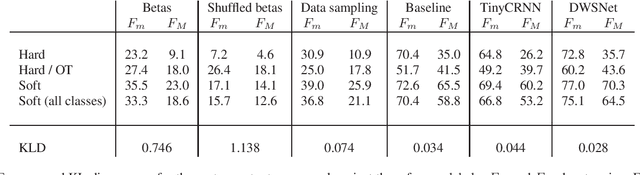
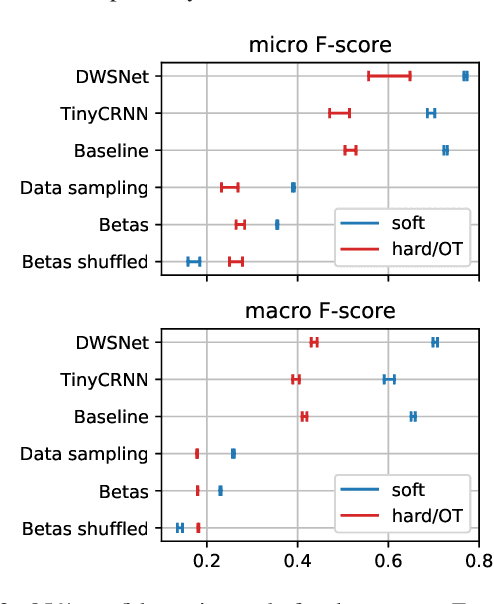
Classification systems are normally trained by minimizing the cross-entropy between system outputs and reference labels, which makes the Kullback-Leibler divergence a natural choice for measuring how closely the system can follow the data. Precision and recall provide another perspective for measuring the performance of a classification system. Non-binary references can arise from various sources, and it is often beneficial to use the soft labels for training instead of the binarized data. However, the existing definitions for precision and recall require binary reference labels, and binarizing the data can cause erroneous interpretations. We present a novel method to calculate precision, recall and F-score without quantizing the data. The proposed metrics extend the well established metrics as the definitions coincide when used with binary labels. To understand the behavior of the metrics we show simple example cases and an evaluation of different sound event detection models trained on real data with soft labels.
Training sound event detection with soft labels from crowdsourced annotations
Feb 28, 2023



In this paper, we study the use of soft labels to train a system for sound event detection (SED). Soft labels can result from annotations which account for human uncertainty about categories, or emerge as a natural representation of multiple opinions in annotation. Converting annotations to hard labels results in unambiguous categories for training, at the cost of losing the details about the labels distribution. This work investigates how soft labels can be used, and what benefits they bring in training a SED system. The results show that the system is capable of learning information about the activity of the sounds which is reflected in the soft labels and is able to detect sounds that are missed in the typical binary target training setup. We also release a new dataset produced through crowdsourcing, containing temporally strong labels for sound events in real-life recordings, with both soft and hard labels.
Crowdsourcing strong labels for sound event detection
Jul 26, 2021
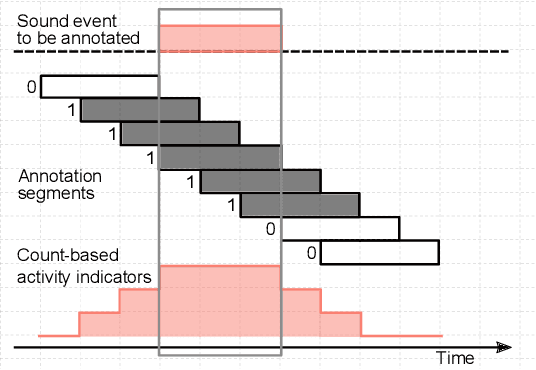
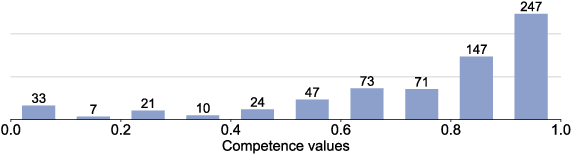

Strong labels are a necessity for evaluation of sound event detection methods, but often scarcely available due to the high resources required by the annotation task. We present a method for estimating strong labels using crowdsourced weak labels, through a process that divides the annotation task into simple unit tasks. Based on estimations of annotators' competence, aggregation and processing of the weak labels results in a set of objective strong labels. The experiment uses synthetic audio in order to verify the quality of the resulting annotations through comparison with ground truth. The proposed method produces labels with high precision, though not all event instances are recalled. Detection metrics comparing the produced annotations with the ground truth show 80% F-score in 1 s segments, and up to 89.5% intersection-based F1-score calculated according to the polyphonic sound detection score metrics.