 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVD:A Novel Methodology and Dataset for Acoustic Vehicle Type Classification
Sep 07, 2023Rising urban populations have led to a surge in vehicle use and made traffic monitoring and management indispensable. Acoustic traffic monitoring (ATM) offers a cost-effective and efficient alternative to more computationally expensive methods of monitoring traffic such as those involving computer vision technologies. In this paper, we present MVD and MVDA: two open datasets for the development of acoustic traffic monitoring and vehicle-type classification algorithms, which contain audio recordings of moving vehicles. The dataset contain four classes- Trucks, Cars, Motorbikes, and a No-vehicle class. Additionally, we propose a novel and efficient way to accurately classify these acoustic signals using cepstrum and spectrum based local and global audio features, and a multi-input neural network. Experimental results show that our methodology improves upon the established baselines of previous works and achieves an accuracy of 91.98% and 96.66% on MVD and MVDA Datasets, respectively. Finally, the proposed model was deployed through an Android application to make it accessible for testing and demonstrate its efficacy.
A Lightweight Deep Learning Model for Human Activity Recognition on Edge Devices
Sep 20, 2019
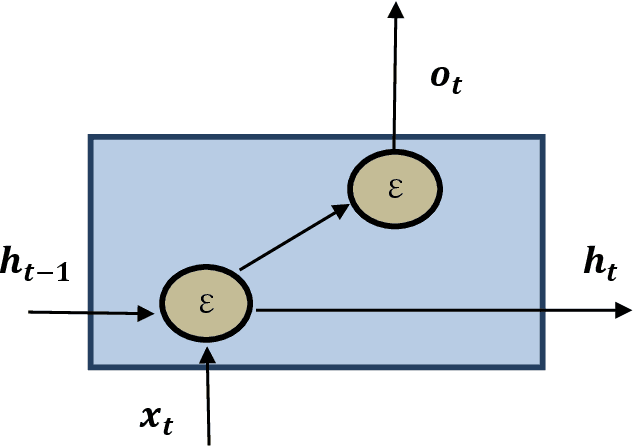
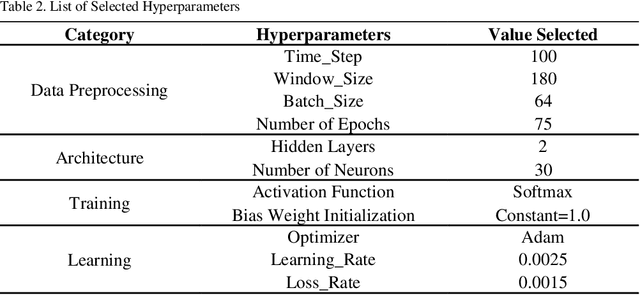
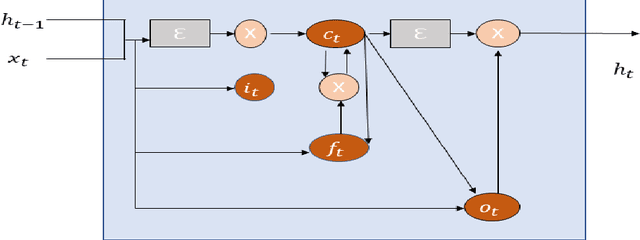
Human Activity Recognition (HAR) using wearable and mobile sensors has gained momentum in last few years, in various fields, such as, healthcare, surveillance, education, entertainment. Nowadays, Edge Computing has emerged to reduce communication latency and network traffic.Edge devices are resource constrained devices and cannot support high computation. In literature, various models have been developed for HAR. In recent years, deep learning algorithms have shown high performance in HAR, but these algorithms require lot of computation making them inefficient to be deployed on edge devices. This paper, proposes a Lightweight Deep Learning Model for HAR requiring less computational power, making it suitable to be deployed on edge devices. The performance of proposed model is tested on the participants six daily activities data. Results show that the proposed model outperforms many of the existing machine learning and deep learning techniques.
Recurrent Neural Network Based Hybrid Model of Gene Regulatory Network
Nov 13, 2015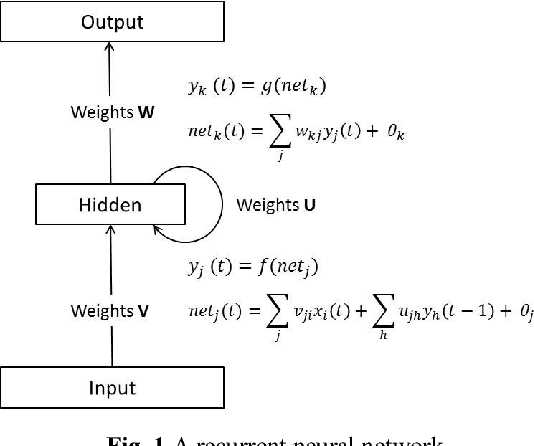

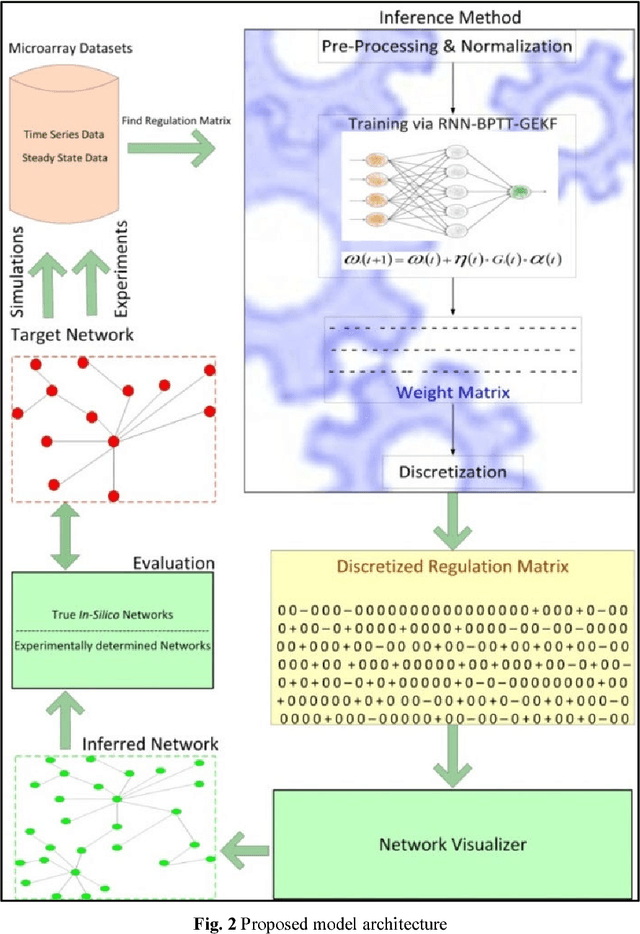
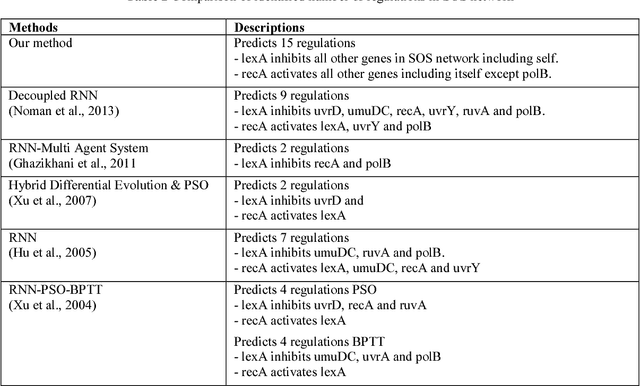
Systems biology is an emerging interdisciplinary area of research that focuses on study of complex interactions in a biological system, such as gene regulatory networks. The discovery of gene regulatory networks leads to a wide range of applications, such as pathways related to a disease that can unveil in what way the disease acts and provide novel tentative drug targets. In addition, the development of biological models from discovered networks or pathways can help to predict the responses to disease and can be much useful for the novel drug development and treatments. The inference of regulatory networks from biological data is still in its infancy stage. This paper proposes a recurrent neural network (RNN) based gene regulatory network (GRN) model hybridized with generalized extended Kalman filter for weight update in backpropagation through time training algorithm. The RNN is a complex neural network that gives a better settlement between the biological closeness and mathematical flexibility to model GRN. The RNN is able to capture complex, non-linear and dynamic relationship among variables. Gene expression data are inherently noisy and Kalman filter performs well for estimation even in noisy data. Hence, non-linear version of Kalman filter, i.e., generalized extended Kalman filter has been applied for weight update during network training. The developed model has been applied on DNA SOS repair network, IRMA network, and two synthetic networks from DREAM Challenge. We compared our results with other state-of-the-art techniques that show superiority of our model. Further, 5% Gaussian noise has been added in the dataset and result of the proposed model shows negligible effect of noise on the results.
* 18 pages, 9 figures and 4 tables
Dengue disease prediction using weka data mining tool
Feb 18, 2015



Dengue is a life threatening disease prevalent in several developed as well as developing countries like India.In this paper we discuss various algorithm approaches of data mining that have been utilized for dengue disease prediction. Data mining is a well known technique used by health organizations for classification of diseases such as dengue, diabetes and cancer in bioinformatics research. In the proposed approach we have used WEKA with 10 cross validation to evaluate data and compare results. Weka has an extensive collection of different machine learning and data mining algorithms. In this paper we have firstly classified the dengue data set and then compared the different data mining techniques in weka through Explorer, knowledge flow and Experimenter interfaces. Furthermore in order to validate our approach we have used a dengue dataset with 108 instances but weka used 99 rows and 18 attributes to determine the prediction of disease and their accuracy using classifications of different algorithms to find out the best performance. The main objective of this paper is to classify data and assist the users in extracting useful information from data and easily identify a suitable algorithm for accurate predictive model from it. From the findings of this paper it can be concluded that Na\"ive Bayes and J48 are the best performance algorithms for classified accuracy because they achieved maximum accuracy= 100% with 99 correctly classified instances, maximum ROC = 1, had least mean absolute error and it took minimum time for building this model through Explorer and Knowledge flow results