 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient comparison of sentence embeddings
Apr 02, 2022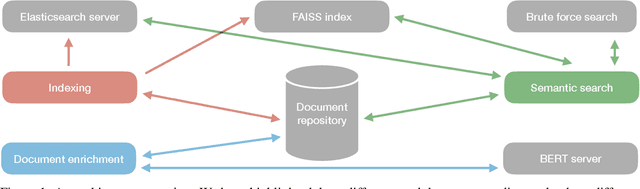

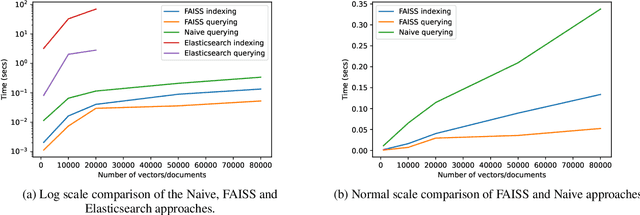

The domain of natural language processing (NLP), which has greatly evolved over the last years, has highly benefited from the recent developments in word and sentence embeddings. Such embeddings enable the transformation of complex NLP tasks, like semantic similarity or Question and Answering (Q\&A), into much simpler to perform vector comparisons. However, such a problem transformation raises new challenges like the efficient comparison of embeddings and their manipulation. In this work, we will discuss about various word and sentence embeddings algorithms, we will select a sentence embedding algorithm, BERT, as our algorithm of choice and we will evaluate the performance of two vector comparison approaches, FAISS and Elasticsearch, in the specific problem of sentence embeddings. According to the results, FAISS outperforms Elasticsearch when used in a centralized environment with only one node, especially when big datasets are included.
Method and apparatus for automatic text input insertion in digital devices with a restricted number of keys
Jul 29, 2017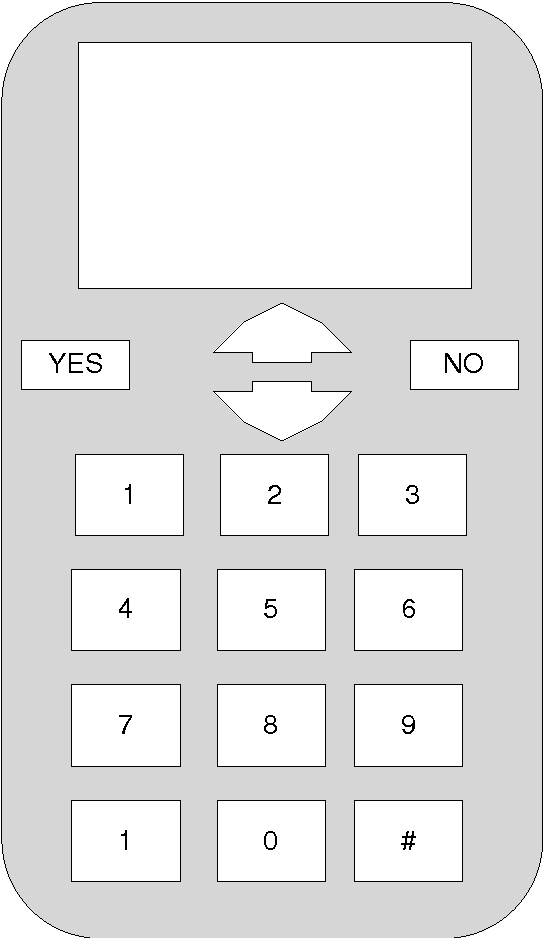
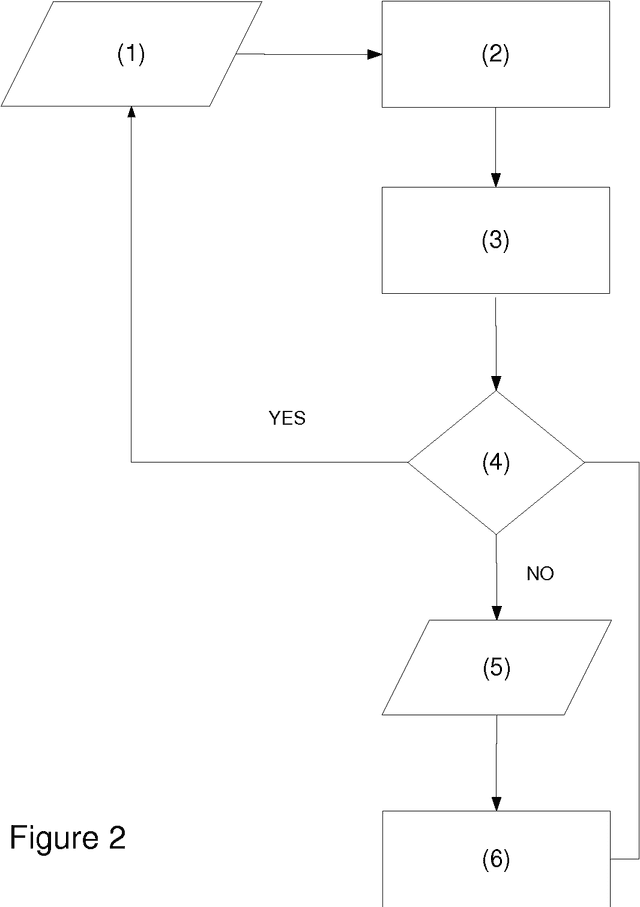
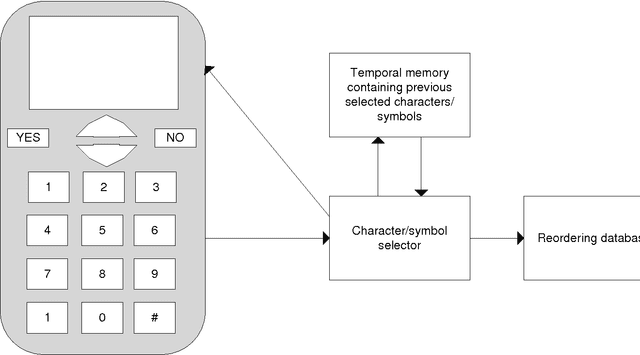
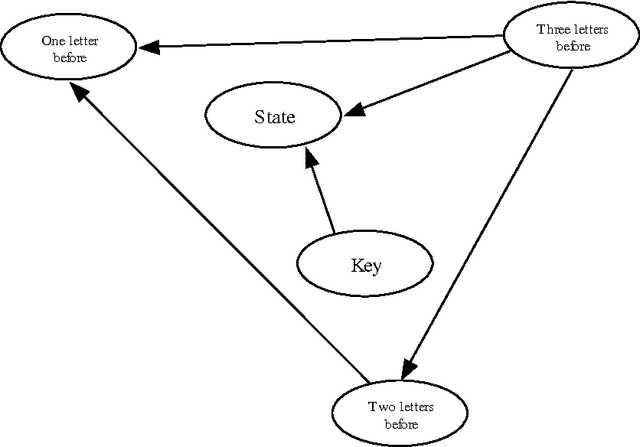
A device which contains number of symbol input keys, where the number of available keys is less than the number of symbols of an alphabet of any given language, screen, and dynamic reordering table of the symbols which are mapped onto those keys, according to a disambiguation method based on the previously entered symbols. The device incorporates a previously entered keystrokes tracking mechanism, and the key selected by the user detector, as well as a mechanism to select the dynamic symbol reordering mapped onto this key according to the information contained to the reordering table. The reordering table occurs from a disambiguation method which reorders the symbol appearance. The reordering information occurs from Bayesian Belief network construction and training from text corpora of the specific language.