 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Preparing Data of Industrial Processes for Machine Learning Applications
Sep 08, 2021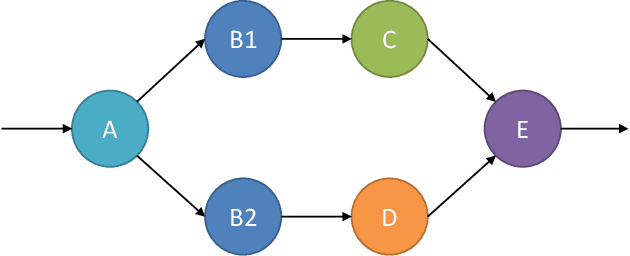

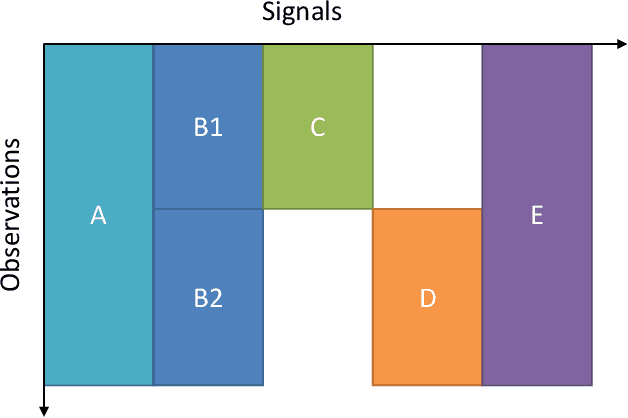
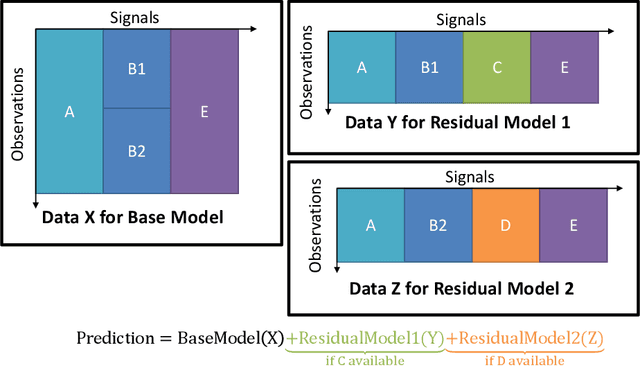
Industrial applications of machine learning face unique challenges due to the nature of raw industry data. Preprocessing and preparing raw industrial data for machine learning applications is a demanding task that often takes more time and work than the actual modeling process itself and poses additional challenges. This paper addresses one of those challenges, specifically, the challenge of missing values due to sensor unavailability at different production units of nonlinear production lines. In cases where only a small proportion of the data is missing, those missing values can often be imputed. In cases of large proportions of missing data, imputing is often not feasible, and removing observations containing missing values is often the only option. This paper presents a technique, that allows to utilize all of the available data without the need of removing large amounts of observations where data is only partially available. We do not only discuss the principal idea of the presented method, but also show different possible implementations that can be applied depending on the data at hand. Finally, we demonstrate the application of the presented method with data from a steel production plant.
* International Conference on Computer Aided Systems Theory, Eurocast 2019, pp 413-420