 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deep Learning for Augmentation of sRNA Expression Profiles
Sep 26, 2019



The lack of well-structured metadata annotations complicates there-usability and interpretation of the growing amount of publicly available RNA expression data. The machine learning-based prediction of metadata(data augmentation) can considerably improve the quality of expression data annotation. In this study,we systematically benchmark deep learning (DL) and random forest (RF)-based metadata augmentation of tissue, age, and sex using small RNA (sRNA) expression profiles. We use 4243 annotated sRNA-Seq samples from the small RNA expression atlas (SEA) database to train and test the augmentation performance. In general, the DL machine learner outperforms the RF method in almost all tested cases. The average cross-validated prediction accuracy of the DL algorithm for tissues is 96.5%, for sex is 77%, and for age is 77.2%. The average tissue prediction accuracy for a completely new dataset is 83.1% (DL) and 80.8% (RF). To understand which sRNAs influence DL predictions, we employ backpropagation-based feature importance scores using the DeepLIFT method, which enable us to obtain information on biological relevance of sRNAs.
Deep Learning and Random Forest-Based Augmentation of sRNA Expression Profiles
Sep 26, 2019
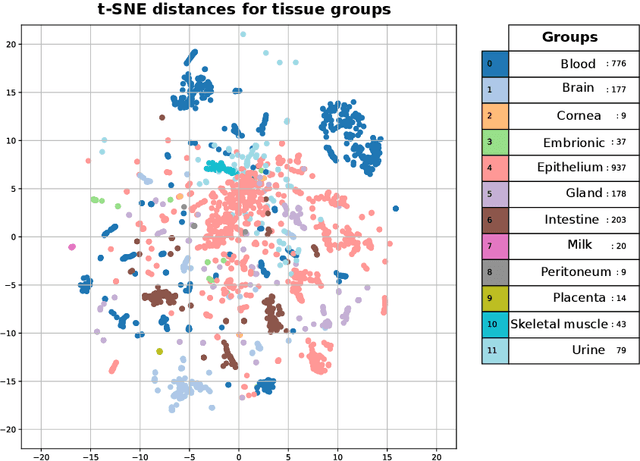

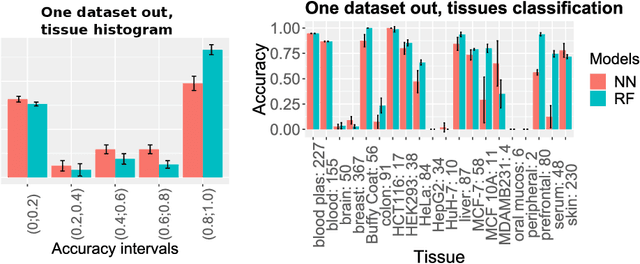
The lack of well-structured annotations in a growing amount of RNA expression data complicates data interoperability and reusability. Commonly - used text mining methods extract annotations from existing unstructured data descriptions and often provide inaccurate output that requires manual curation. Automatic data-based augmentation (generation of annotations on the base of expression data) can considerably improve the annotation quality and has not been well-studied. We formulate an automatic augmentation of small RNA-seq expression data as a classification problem and investigate deep learning (DL) and random forest (RF) approaches to solve it. We generate tissue and sex annotations from small RNA-seq expression data for tissues and cell lines of homo sapiens. We validate our approach on 4243 annotated small RNA-seq samples from the Small RNA Expression Atlas (SEA) database. The average prediction accuracy for tissue groups is 98% (DL), for tissues - 96.5% (DL), and for sex - 77% (DL). The "one dataset out" average accuracy for tissue group prediction is 83% (DL) and 59% (RF). On average, DL provides better results as compared to RF, and considerably improves classification performance for 'unseen' datasets.