 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Trust in Contextual Bandits
Mar 09, 2026Standard approaches to Robust Reinforcement Learning assume that feedback sources are either globally trustworthy or globally adversarial. In this paper, we challenge this assumption and we identify a more subtle failure mode. We term this mode as Contextual Sycophancy, where evaluators are truthful in benign contexts but strategically biased in critical ones. We prove that standard robust methods fail in this setting, suffering from Contextual Objective Decoupling. To address this, we propose CESA-LinUCB, which learns a high-dimensional Trust Boundary for each evaluator. We prove that CESA-LinUCB achieves sublinear regret $\tilde{O}(\sqrt{T})$ against contextual adversaries, recovering the ground truth even when no evaluator is globally reliable.
Objective Decoupling in Social Reinforcement Learning: Recovering Ground Truth from Sycophantic Majorities
Feb 08, 2026Contemporary AI alignment strategies rely on a fragile premise: that human feedback, while noisy, remains a fundamentally truthful signal. In this paper, we identify this assumption as Dogma 4 of Reinforcement Learning (RL). We demonstrate that while this dogma holds in static environments, it fails in social settings where evaluators may be sycophantic, lazy, or adversarial. We prove that under Dogma 4, standard RL agents suffer from what we call Objective Decoupling, a structural failure mode where the agent's learned objective permanently separates from the latent ground truth, guaranteeing convergence to misalignment. To resolve this, we propose Epistemic Source Alignment (ESA). Unlike standard robust methods that rely on statistical consensus (trusting the majority), ESA utilizes sparse safety axioms to judge the source of the feedback rather than the signal itself. We prove that this "judging the judges" mechanism guarantees convergence to the true objective, even when a majority of evaluators are biased. Empirically, we show that while traditional consensus methods fail under majority collusion, our approach successfully recovers the optimal policy.
Comprehensive Survey of Reinforcement Learning: From Algorithms to Practical Challenges
Nov 28, 2024



Reinforcement Learning (RL) has emerged as a powerful paradigm in Artificial Intelligence (AI), enabling agents to learn optimal behaviors through interactions with their environments. Drawing from the foundations of trial and error, RL equips agents to make informed decisions through feedback in the form of rewards or penalties. This paper presents a comprehensive survey of RL, meticulously analyzing a wide range of algorithms, from foundational tabular methods to advanced Deep Reinforcement Learning (DRL) techniques. We categorize and evaluate these algorithms based on key criteria such as scalability, sample efficiency, and suitability. We compare the methods in the form of their strengths and weaknesses in diverse settings. Additionally, we offer practical insights into the selection and implementation of RL algorithms, addressing common challenges like convergence, stability, and the exploration-exploitation dilemma. This paper serves as a comprehensive reference for researchers and practitioners aiming to harness the full potential of RL in solving complex, real-world problems.
An Introduction to Reinforcement Learning: Fundamental Concepts and Practical Applications
Aug 13, 2024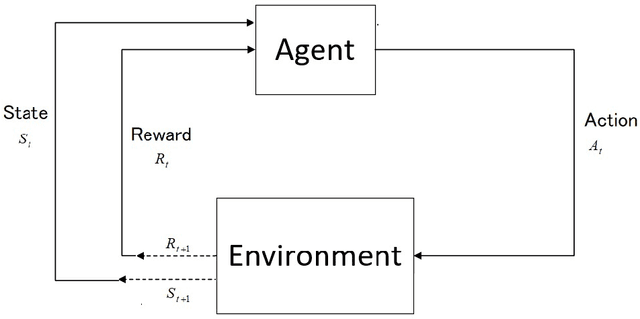


Reinforcement Learning (RL) is a branch of Artificial Intelligence (AI) which focuses on training agents to make decisions by interacting with their environment to maximize cumulative rewards. An overview of RL is provided in this paper, which discusses its core concepts, methodologies, recent trends, and resources for learning. We provide a detailed explanation of key components of RL such as states, actions, policies, and reward signals so that the reader can build a foundational understanding. The paper also provides examples of various RL algorithms, including model-free and model-based methods. In addition, RL algorithms are introduced and resources for learning and implementing them are provided, such as books, courses, and online communities. This paper demystifies a comprehensive yet simple introduction for beginners by offering a structured and clear pathway for acquiring and implementing real-time techniques.