 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning-Based Visual Saliency Prediction Model for Stereoscopic 3D Video (LBVS-3D)
Mar 13, 2018


Over the past decade, many computational saliency prediction models have been proposed for 2D images and videos. Considering that the human visual system has evolved in a natural 3D environment, it is only natural to want to design visual attention models for 3D content. Existing monocular saliency models are not able to accurately predict the attentive regions when applied to 3D image/video content, as they do not incorporate depth information. This paper explores stereoscopic video saliency prediction by exploiting both low-level attributes such as brightness, color, texture, orientation, motion, and depth, as well as high-level cues such as face, person, vehicle, animal, text, and horizon. Our model starts with a rough segmentation and quantifies several intuitive observations such as the effects of visual discomfort level, depth abruptness, motion acceleration, elements of surprise, size and compactness of the salient regions, and emphasizing only a few salient objects in a scene. A new fovea-based model of spatial distance between the image regions is adopted for considering local and global feature calculations. To efficiently fuse the conspicuity maps generated by our method to one single saliency map that is highly correlated with the eye-fixation data, a random forest based algorithm is utilized. The performance of the proposed saliency model is evaluated against the results of an eye-tracking experiment, which involved 24 subjects and an in-house database of 61 captured stereoscopic videos. Our stereo video database as well as the eye-tracking data are publicly available along with this paper. Experiment results show that the proposed saliency prediction method achieves competitive performance compared to the state-of-the-art approaches.
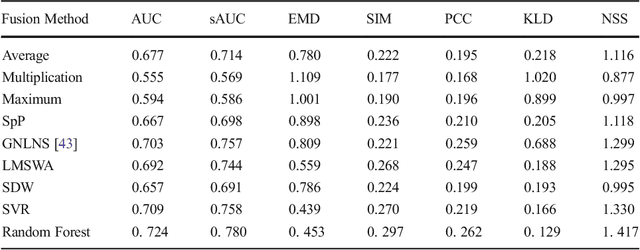
A Learning-Based Visual Saliency Fusion Model for High Dynamic Range Video
Mar 13, 2018



Saliency prediction for Standard Dynamic Range (SDR) videos has been well explored in the last decade. However, limited studies are available on High Dynamic Range (HDR) Visual Attention Models (VAMs). Considering that the characteristic of HDR content in terms of dynamic range and color gamut is quite different than those of SDR content, it is essential to identify the importance of different saliency attributes of HDR videos for designing a VAM and understand how to combine these features. To this end we propose a learning-based visual saliency fusion method for HDR content (LVBS-HDR) to combine various visual saliency features. In our approach various conspicuity maps are extracted from HDR data, and then for fusing conspicuity maps, a Random Forests algorithm is used to train a model based on the collected data from an eye-tracking experiment. Performance evaluations demonstrate the superiority of the proposed fusion method against other existing fusion methods.