 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Driven Structural Decomposition of Dynamic Games via Best Response Maps
Feb 05, 2026Dynamic games are powerful tools to model multi-agent decision-making, yet computing Nash (generalized Nash) equilibria remains a central challenge in such settings. Complexity arises from tightly coupled optimality conditions, nested optimization structures, and poor numerical conditioning. Existing game-theoretic solvers address these challenges by directly solving the joint game, typically requiring explicit modeling of all agents' objective functions and constraints, while learning-based approaches often decouple interaction through prediction or policy approximation, sacrificing equilibrium consistency. This paper introduces a conceptually novel formulation for dynamic games by restructuring the equilibrium computation. Rather than solving a fully coupled game or decoupling agents through prediction or policy approximation, a data-driven structural reduction of the game is proposed that removes nested optimization layers and derivative coupling by embedding an offline-compiled best-response map as a feasibility constraint. Under standard regularity conditions, when the best-response operator is exact, any converged solution of the reduced problem corresponds to a local open-loop Nash (GNE) equilibrium of the original game; with a learned surrogate, the solution is approximately equilibrium-consistent up to the best-response approximation error. The proposed formulation is supported by mathematical proofs, accompanying a large-scale Monte Carlo study in a two-player open-loop dynamic game motivated by the autonomous racing problem. Comparisons are made against state-of-the-art joint game solvers, and results are reported on solution quality, computational cost, and constraint satisfaction.
Optimal Modified Feedback Strategies in LQ Games under Control Imperfections
Mar 24, 2025


Game-theoretic approaches and Nash equilibrium have been widely applied across various engineering domains. However, practical challenges such as disturbances, delays, and actuator limitations can hinder the precise execution of Nash equilibrium strategies. This work explores the impact of such implementation imperfections on game trajectories and players' costs within the context of a two-player linear quadratic (LQ) nonzero-sum game. Specifically, we analyze how small deviations by one player affect the state and cost function of the other player. To address these deviations, we propose an adjusted control policy that not only mitigates adverse effects optimally but can also exploit the deviations to enhance performance. Rigorous mathematical analysis and proofs are presented, demonstrating through a representative example that the proposed policy modification achieves up to $61\%$ improvement compared to the unadjusted feedback policy and up to $0.59\%$ compared to the feedback Nash strategy.
Multi-Step Deep Koopman Network (MDK-Net) for Vehicle Control in Frenet Frame
Mar 04, 2025



The highly nonlinear dynamics of vehicles present a major challenge for the practical implementation of optimal and Model Predictive Control (MPC) approaches in path planning and following. Koopman operator theory offers a global linear representation of nonlinear dynamical systems, making it a promising framework for optimization-based vehicle control. This paper introduces a novel deep learning-based Koopman modeling approach that employs deep neural networks to capture the full vehicle dynamics-from pedal and steering inputs to chassis states-within a curvilinear Frenet frame. The superior accuracy of the Koopman model compared to identified linear models is shown for a double lane change maneuver. Furthermore, it is shown that an MPC controller deploying the Koopman model provides significantly improved performance while maintaining computational efficiency comparable to a linear MPC.
An Automatic Tuning MPC with Application to Ecological Cruise Control
Sep 17, 2023
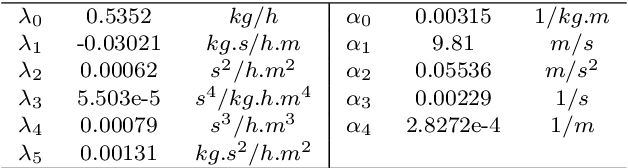
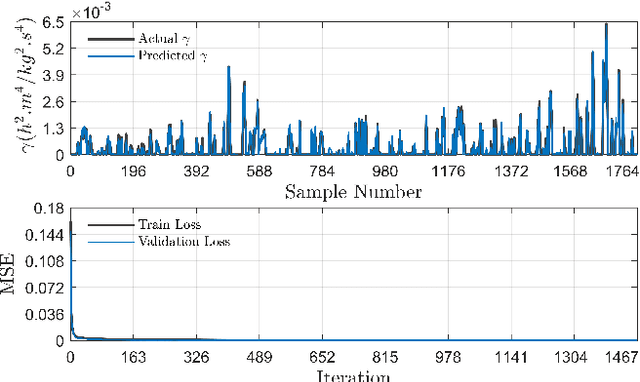

Model predictive control (MPC) is a powerful tool for planning and controlling dynamical systems due to its capacity for handling constraints and taking advantage of preview information. Nevertheless, MPC performance is highly dependent on the choice of cost function tuning parameters. In this work, we demonstrate an approach for online automatic tuning of an MPC controller with an example application to an ecological cruise control system that saves fuel by using a preview of road grade. We solve the global fuel consumption minimization problem offline using dynamic programming and find the corresponding MPC cost function by solving the inverse optimization problem. A neural network fitted to these offline results is used to generate the desired MPC cost function weight during online operation. The effectiveness of the proposed approach is verified in simulation for different road geometries.