 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Startup Success with Text Analysis
Dec 11, 2023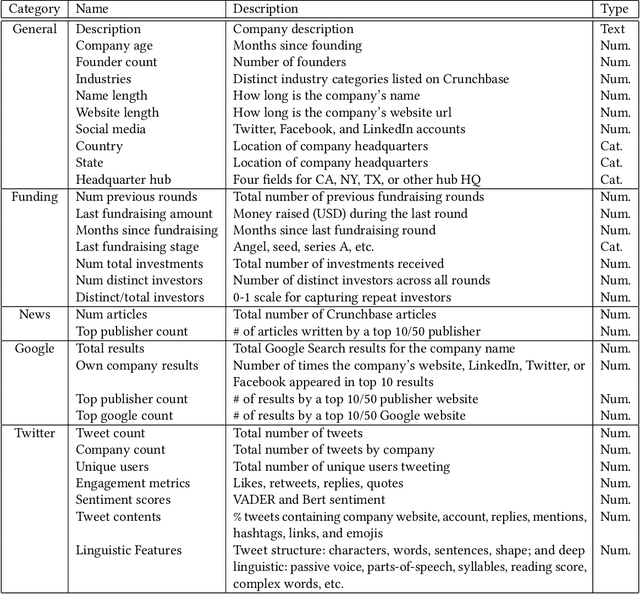
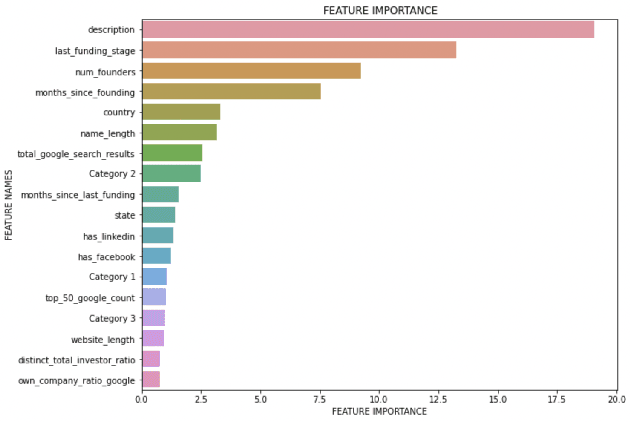

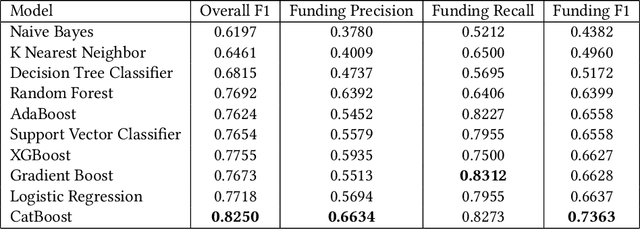
Investors are interested in predicting future success of startup companies, preferably using publicly available data which can be gathered using free online sources. Using public-only data has been shown to work, but there is still much room for improvement. Two of the best performing prediction experiments use 17 and 49 features respectively, mostly numeric and categorical in nature. In this paper, we significantly expand and diversify both the sources and the number of features (to 171) to achieve better prediction. Data collected from Crunchbase, the Google Search API, and Twitter (now X) are used to predict whether a company will raise a round of funding within a fixed time horizon. Much of the new features are textual and the Twitter subset include linguistic metrics such as measures of passive voice and parts-of-speech. A total of ten machine learning models are also evaluated for best performance. The adaptable model can be used to predict funding 1-5 years into the future, with a variable cutoff threshold to favor either precision or recall. Prediction with comparable assumptions generally achieves F scores above 0.730 which outperforms previous attempts in the literature (0.531), and does so with fewer examples. Furthermore, we find that the vast majority of the performance impact comes from the top 18 of 171 features which are mostly generic company observations, including the best performing individual feature which is the free-form text description of the company.