 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Unsupervised Federated Learning Approach for Anomaly Detection in Heterogeneous IoT Networks
Feb 27, 2026Federated learning (FL) is an effective paradigm for distributed environments such as the Internet of Things (IoT), where data from diverse devices with varying functionalities remains localized while contributing to a shared global model. By eliminating the need to transmit raw data, FL inherently preserves privacy. However, the heterogeneous nature of IoT data, stemming from differences in device capabilities, data formats, and communication constraints, poses significant challenges to maintaining both global model performance and privacy. In the context of IoT-based anomaly detection, unsupervised FL offers a promising means to identify abnormal behavior without centralized data aggregation. Nevertheless, feature heterogeneity across devices complicates model training and optimization, hindering effective implementation. In this study we propose an efficient unsupervised FL framework that enhances anomaly detection by leveraging shared features from two distinct IoT datasets: one focused on anomaly detection and the other on device identification, while preserving dataset-specific features. To improve transparency and interpretability, we employ explainable AI techniques, such as SHAP, to identify key features influencing local model decisions. Experiments conducted on real-world IoT datasets demonstrate that the proposed method significantly outperforms conventional FL approaches in anomaly detection accuracy. This work underscores the potential of using shared features from complementary datasets to optimize unsupervised federated learning and achieve superior anomaly detection results in decentralized IoT environments.
Security Threat Modeling for Emerging AI-Agent Protocols: A Comparative Analysis of MCP, A2A, Agora, and ANP
Feb 11, 2026The rapid development of the AI agent communication protocols, including the Model Context Protocol (MCP), Agent2Agent (A2A), Agora, and Agent Network Protocol (ANP), is reshaping how AI agents communicate with tools, services, and each other. While these protocols support scalable multi-agent interaction and cross-organizational interoperability, their security principles remain understudied, and standardized threat modeling is limited; no protocol-centric risk assessment framework has been established yet. This paper presents a systematic security analysis of four emerging AI agent communication protocols. First, we develop a structured threat modeling analysis that examines protocol architectures, trust assumptions, interaction patterns, and lifecycle behaviors to identify protocol-specific and cross-protocol risk surfaces. Second, we introduce a qualitative risk assessment framework that identifies twelve protocol-level risks and evaluates security posture across the creation, operation, and update phases through systematic assessment of likelihood, impact, and overall protocol risk, with implications for secure deployment and future standardization. Third, we provide a measurement-driven case study on MCP that formalizes the risk of missing mandatory validation/attestation for executable components as a falsifiable security claim by quantifying wrong-provider tool execution under multi-server composition across representative resolver policies. Collectively, our results highlight key design-induced risk surfaces and provide actionable guidance for secure deployment and future standardization of agent communication ecosystems.
CIC-Trap4Phish: A Unified Multi-Format Dataset for Phishing and Quishing Attachment Detection
Feb 09, 2026Phishing attacks represents one of the primary attack methods which is used by cyber attackers. In many cases, attackers use deceptive emails along with malicious attachments to trick users into giving away sensitive information or installing malware while compromising entire systems. The flexibility of malicious email attachments makes them stand out as a preferred vector for attackers as they can embed harmful content such as malware or malicious URLs inside standard document formats. Although phishing email defenses have improved a lot, attackers continue to abuse attachments, enabling malicious content to bypass security measures. Moreover, another challenge that researches face in training advance models, is lack of an unified and comprehensive dataset that covers the most prevalent data types. To address this gap, we generated CIC-Trap4Phish, a multi-format dataset containing both malicious and benign samples across five categories commonly used in phishing campaigns: Microsoft Word documents, Excel spreadsheets, PDF files, HTML pages, and QR code images. For the first four file types, a set of execution-free static feature pipeline was proposed, designed to capture structural, lexical, and metadata-based indicators without the need to open or execute files. Feature selection was performed using a combination of SHAP analysis and feature importance, yielding compact, discriminative feature subsets for each file type. The selected features were evaluated by using lightweight machine learning models, including Random Forest, XGBoost, and Decision Tree. All models demonstrate high detection accuracy across formats. For QR code-based phishing (quishing), two complementary methods were implemented: image-based detection by employing Convolutional Neural Networks (CNNs) and lexical analysis of decoded URLs using recent lightweight language models.
Natural Language Processing via LDA Topic Model in Recommendation Systems
Sep 20, 2019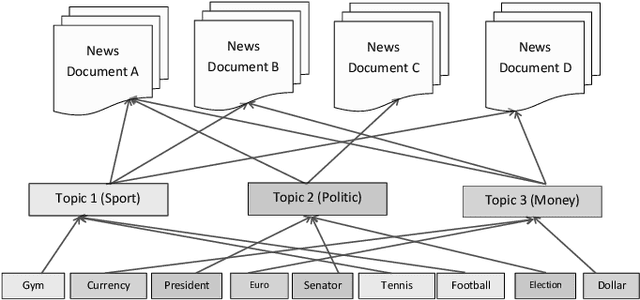
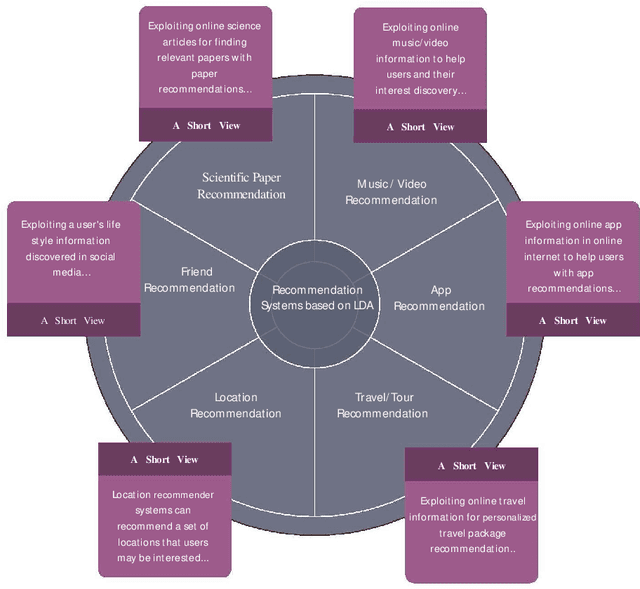
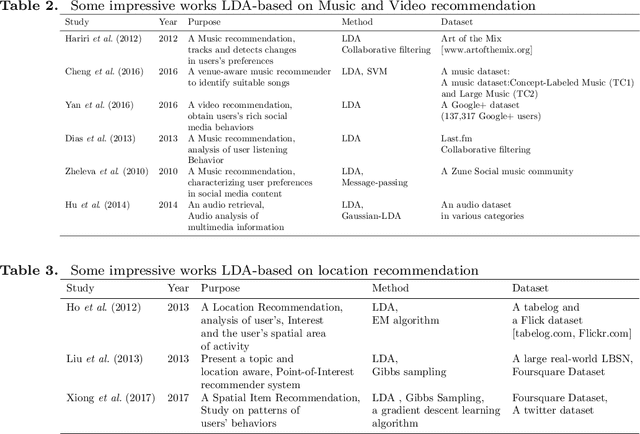
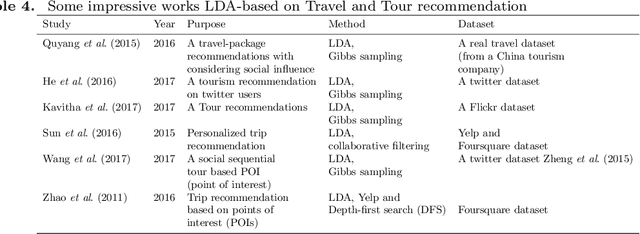
Today, Internet is one of the widest available media worldwide. Recommendation systems are increasingly being used in various applications such as movie recommendation, mobile recommendation, article recommendation and etc. Collaborative Filtering (CF) and Content-Based (CB) are Well-known techniques for building recommendation systems. Topic modeling based on LDA, is a powerful technique for semantic mining and perform topic extraction. In the past few years, many articles have been published based on LDA technique for building recommendation systems. In this paper, we present taxonomy of recommendation systems and applications based on LDA. In addition, we utilize LDA and Gibbs sampling algorithms to evaluate ISWC and WWW conference publications in computer science. Our study suggest that the recommendation systems based on LDA could be effective in building smart recommendation system in online communities.
Recommendation System based on Semantic Scholar Mining and Topic modeling: A behavioral analysis of researchers from six conferences
Dec 20, 2018
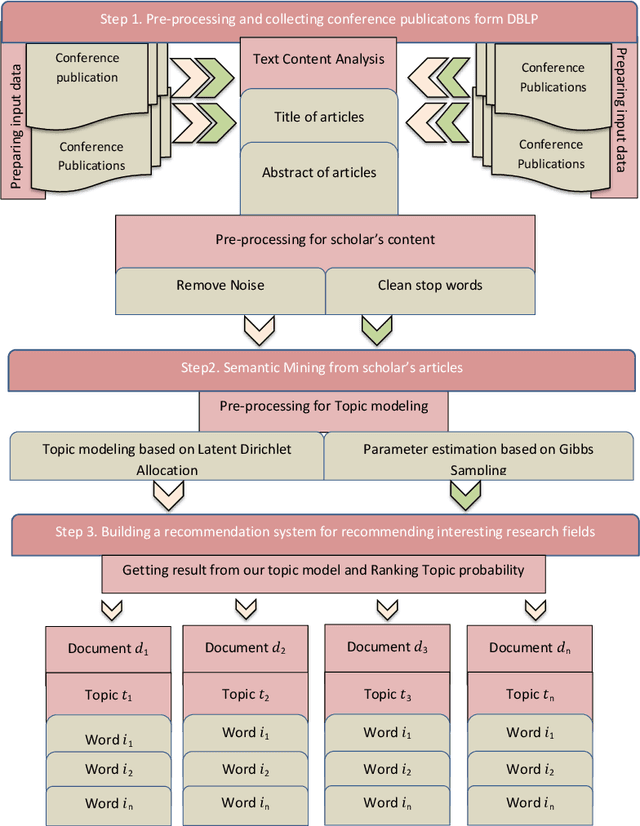
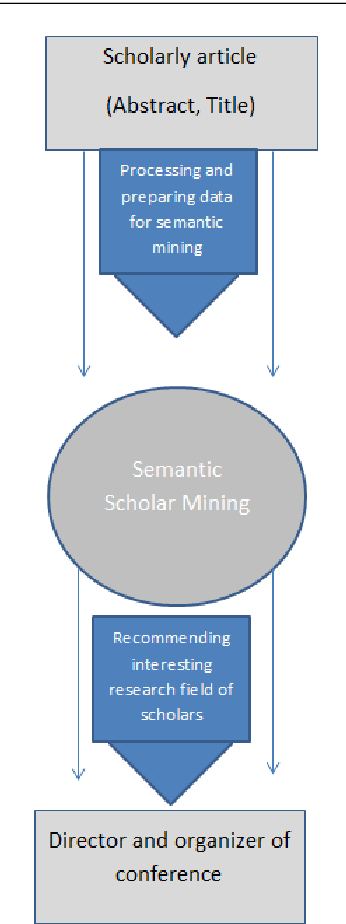
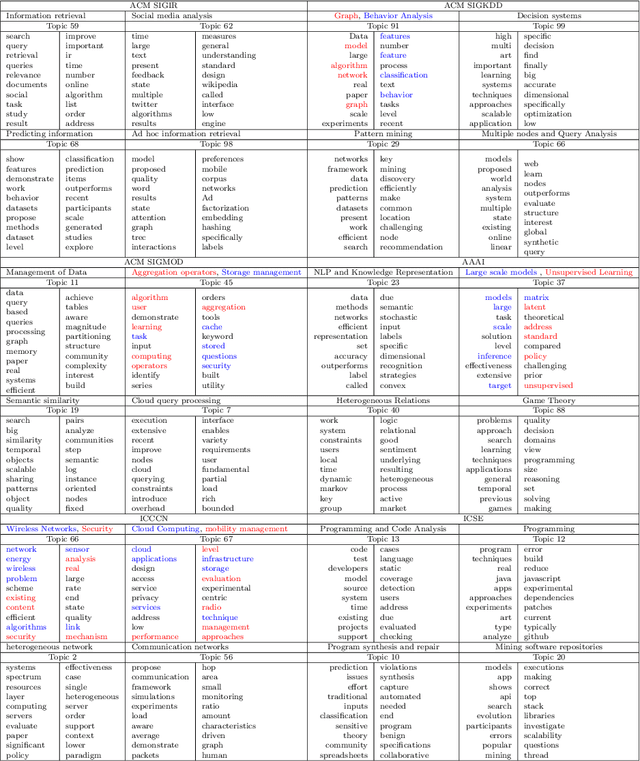
Recommendation systems have an important place to help online users in the internet society. Recommendation Systems in computer science are of very practical use these days in various aspects of the Internet portals, such as social networks, and library websites. There are several approaches to implement recommendation systems, Latent Dirichlet Allocation (LDA) is one the popular techniques in Topic Modeling. Recently, researchers have proposed many approaches based on Recommendation Systems and LDA. According to importance of the subject, in this paper we discover the trends of the topics and find relationship between LDA topics and Scholar-Context-documents. In fact, We apply probabilistic topic modeling based on Gibbs sampling algorithms for a semantic mining from six conference publications in computer science from DBLP dataset. According to our experimental results, our semantic framework can be effective to help organizations to better organize these conferences and cover future research topics.