 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation to Improve Large Language Models in Food Hazard and Product Detection
Feb 12, 2025The primary objective of this study is to demonstrate the impact of data augmentation using ChatGPT-4o-mini on food hazard and product analysis. The augmented data is generated using ChatGPT-4o-mini and subsequently used to train two large language models: RoBERTa-base and Flan-T5-base. The models are evaluated on test sets. The results indicate that using augmented data helped improve model performance across key metrics, including recall, F1 score, precision, and accuracy, compared to using only the provided dataset. The full code, including model training and the augmented dataset, can be found in this repository: https://github.com/AREEG94FAHAD/food-hazard-prdouct-cls
YOLOv11 Optimization for Efficient Resource Utilization
Dec 19, 2024



The objective of this research is to optimize the eleventh iteration of You Only Look Once (YOLOv11) by developing size-specific modified versions of the architecture. These modifications involve pruning unnecessary layers and reconfiguring the main architecture of YOLOv11. Each proposed version is tailored to detect objects of specific size ranges, from small to large. To ensure proper model selection based on dataset characteristics, we introduced an object classifier program. This program identifies the most suitable modified version for a given dataset. The proposed models were evaluated on various datasets and compared with the original YOLOv11 and YOLOv8 models. The experimental results highlight significant improvements in computational resource efficiency, with the proposed models maintaining the accuracy of the original YOLOv11. In some cases, the modified versions outperformed the original model regarding detection performance. Furthermore, the proposed models demonstrated reduced model sizes and faster inference times. Models weights and the object size classifier can be found in this repository
TaskComplexity: A Dataset for Task Complexity Classification with In-Context Learning, FLAN-T5 and GPT-4o Benchmarks
Sep 30, 2024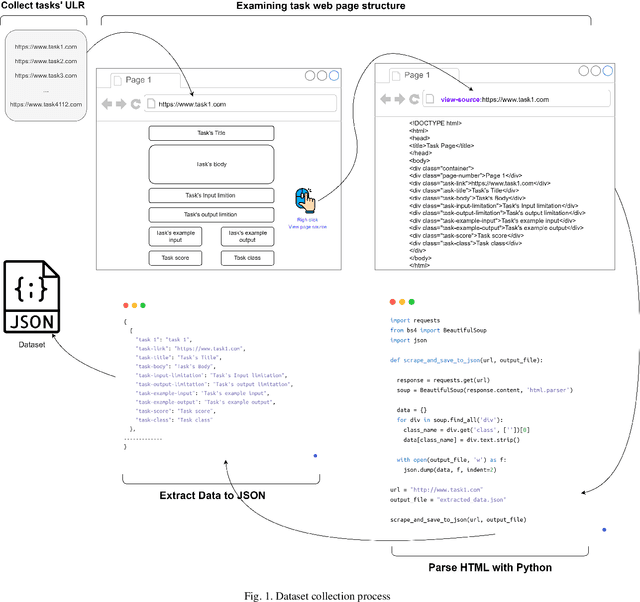
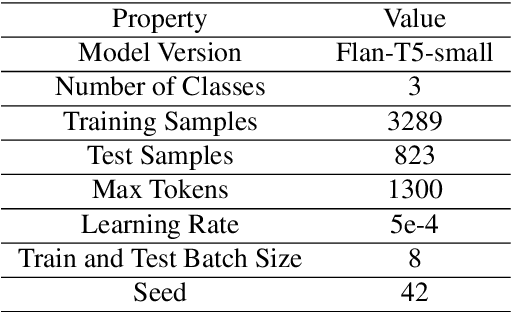
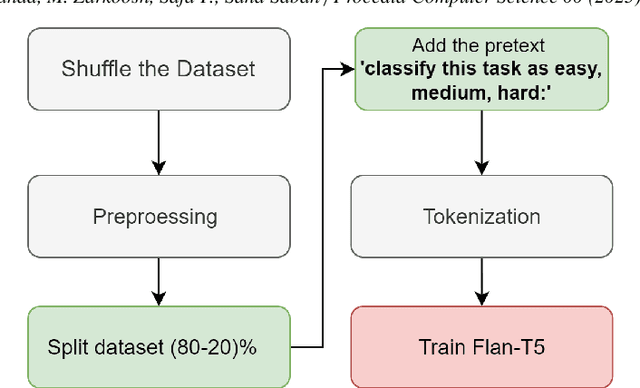
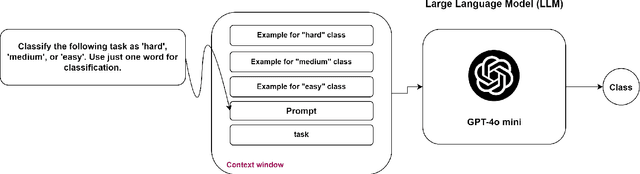
This paper addresses the challenge of classifying and assigning programming tasks to experts, a process that typically requires significant effort, time, and cost. To tackle this issue, a novel dataset containing a total of 4,112 programming tasks was created by extracting tasks from various websites. Web scraping techniques were employed to collect this dataset of programming problems systematically. Specific HTML tags were tracked to extract key elements of each issue, including the title, problem description, input-output, examples, problem class, and complexity score. Examples from the dataset are provided in the appendix to illustrate the variety and complexity of tasks included. The dataset's effectiveness has been evaluated and benchmarked using two approaches; the first approach involved fine-tuning the FLAN-T5 small model on the dataset, while the second approach used in-context learning (ICL) with the GPT-4o mini. The performance was assessed using standard metrics: accuracy, recall, precision, and F1-score. The results indicated that in-context learning with GPT-4o-mini outperformed the FLAN-T5 model.