 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Constrained Autoencoding
May 08, 2020

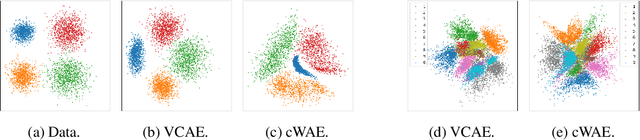

Recent state-of-the-art autoencoder based generative models have an encoder-decoder structure and learn a latent representation with a pre-defined distribution that can be sampled from. Implementing the encoder networks of these models in a stochastic manner provides a natural and common approach to avoid overfitting and enforce a smooth decoder function. However, we show that for stochastic encoders, simultaneously attempting to enforce a distribution constraint and minimising an output distortion leads to a reduction in generative and reconstruction quality. In addition, attempting to enforce a latent distribution constraint is not reasonable when performing disentanglement. Hence, we propose the variance-constrained autoencoder (VCAE), which only enforces a variance constraint on the latent distribution. Our experiments show that VCAE improves upon Wasserstein Autoencoder and the Variational Autoencoder in both reconstruction and generative quality on MNIST and CelebA. Moreover, we show that VCAE equipped with a total correlation penalty term performs equivalently to FactorVAE at learning disentangled representations on 3D-Shapes while being a more principled approach.