 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of machine learning technique for a fast forecast of aggregation kinetics in space-inhomogeneous systems
Dec 07, 2023Modeling of aggregation processes in space-inhomogeneous systems is extremely numerically challenging since complicated aggregation equations -- Smoluchowski equations are to be solved at each space point along with the computation of particle propagation. Low rank approximation for the aggregation kernels can significantly speed up the solution of Smoluchowski equations, while particle propagation could be done in parallel. Yet the simulations with many aggregate sizes remain quite resource-demanding. Here, we explore the way to reduce the amount of direct computations with the use of modern machine learning (ML) techniques. Namely, we propose to replace the actual numerical solution of the Smoluchowki equations with the respective density transformations learned with the application of the conditional normalising flow. We demonstrate that the ML predictions for the space distribution of aggregates and their size distribution requires drastically less computation time and agrees fairly well with the results of direct numerical simulations. Such an opportunity of a quick forecast of space-dependent particle size distribution could be important in practice, especially for the online prediction and visualisation of pollution processes, providing a tool with a reasonable tradeoff between the prediction accuracy and the computational time.
A study of first-passage time minimization via Q-learning in heated gridworlds
Oct 05, 2021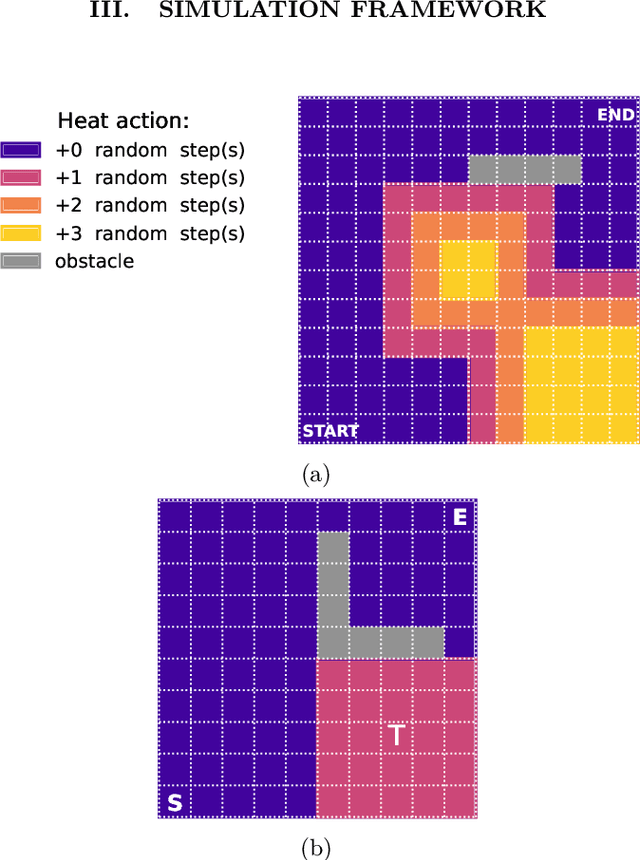

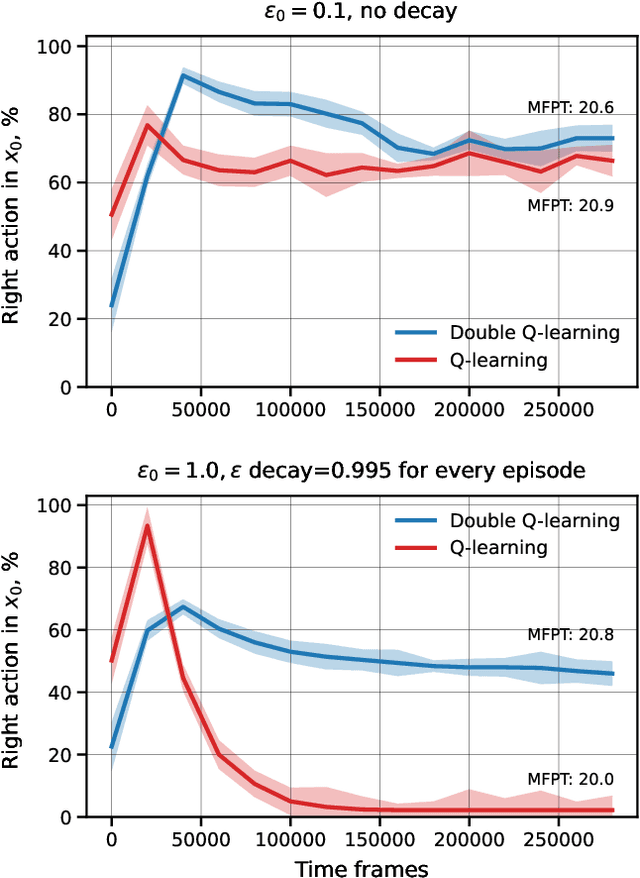
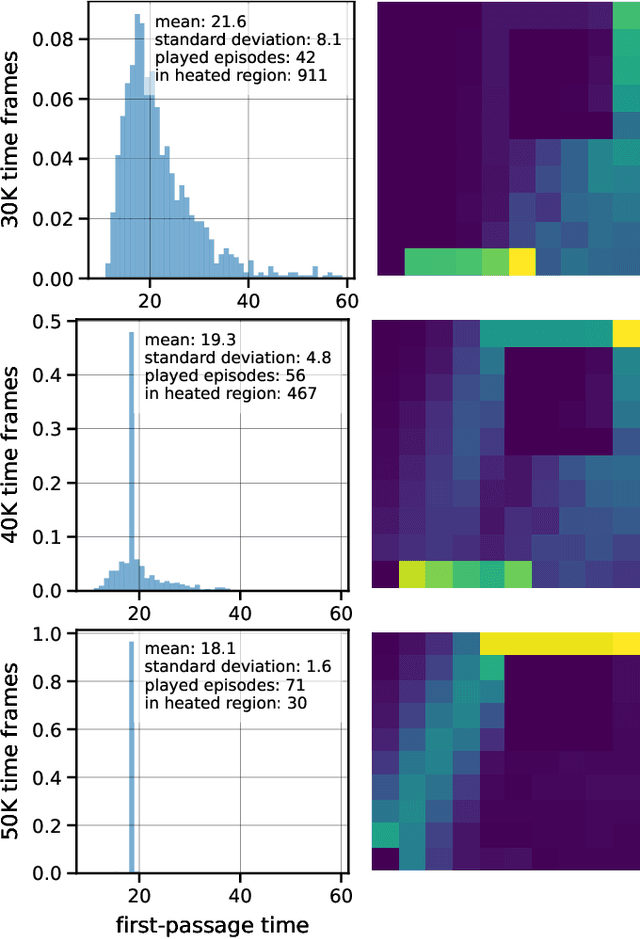
Optimization of first-passage times is required in applications ranging from nanobots navigation to market trading. In such settings, one often encounters unevenly distributed noise levels across the environment. We extensively study how a learning agent fares in 1- and 2- dimensional heated gridworlds with an uneven temperature distribution. The results show certain bias effects in agents trained via simple tabular Q-learning, SARSA, Expected SARSA and Double Q-learning. While high learning rate prevents exploration of regions with higher temperature, low enough rate increases the presence of agents in such regions. The discovered peculiarities and biases of temporal-difference-based reinforcement learning methods should be taken into account in real-world physical applications and agent design.