 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute Human Pose Estimation with Depth Prediction Network
Apr 11, 2019
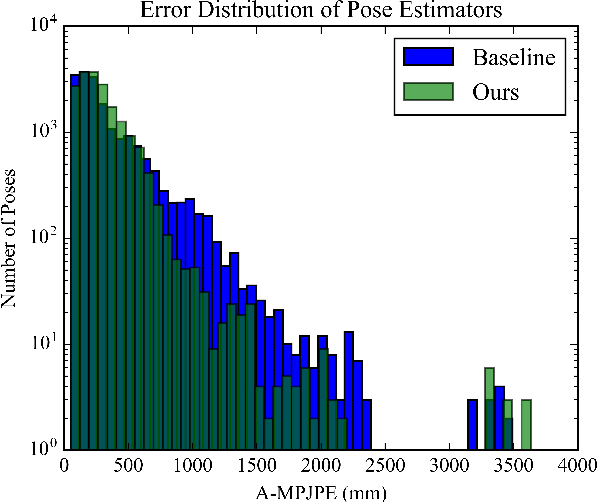
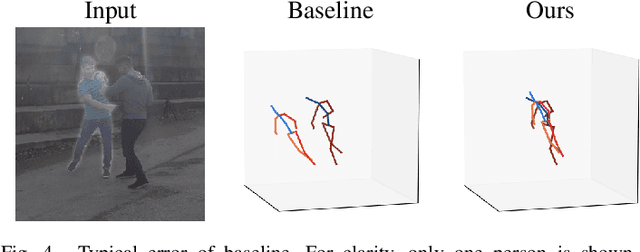
The common approach to 3D human pose estimation is predicting the body joint coordinates relative to the hip. This works well for a single person but is insufficient in the case of multiple interacting people. Methods predicting absolute coordinates first estimate a root-relative pose then calculate the translation via a secondary optimization task. We propose a neural network that predicts joints in a camera centered coordinate system instead of a root-relative one. Unlike previous methods, our network works in a single step without any post-processing. Our network beats previous methods on the MuPoTS-3D dataset and achieves state-of-the-art results.
3D Human Pose Estimation with Siamese Equivariant Embedding
Sep 19, 2018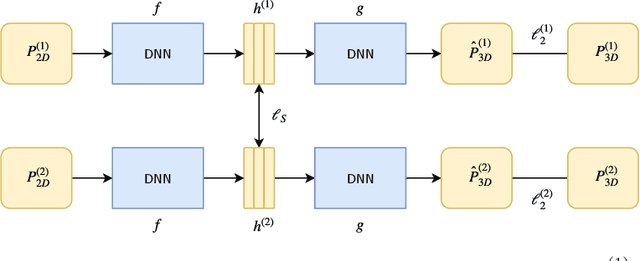
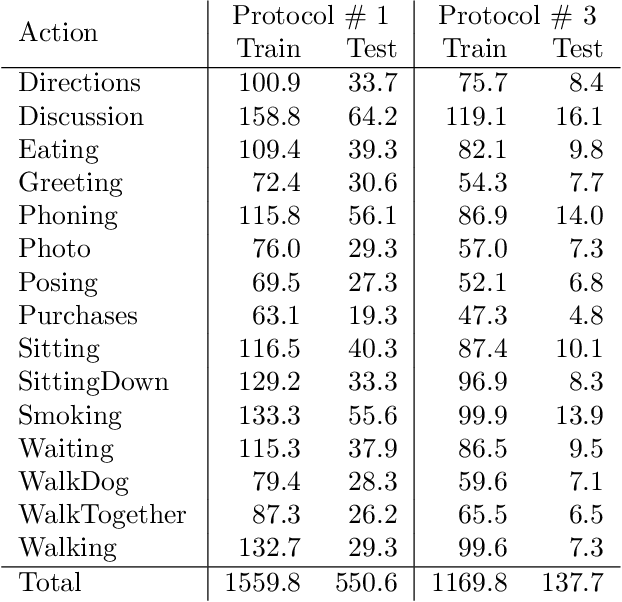
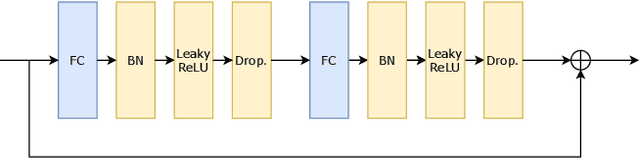
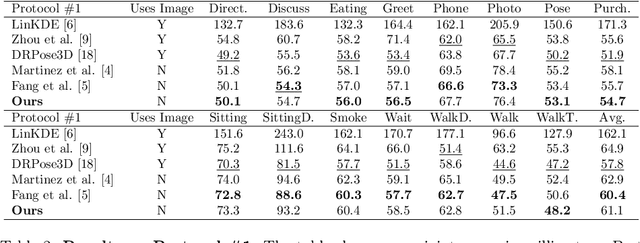
In monocular 3D human pose estimation a common setup is to first detect 2D positions and then lift the detection into 3D coordinates. Many algorithms suffer from overfitting to camera positions in the training set. We propose a siamese architecture that learns a rotation equivariant hidden representation to reduce the need for data augmentation. Our method is evaluated on multiple databases with different base networks and shows a consistent improvement of error metrics. It achieves state-of-the-art cross-camera error rate among algorithms that use estimated 2D joint coordinates only.