 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-values for classification
Jun 26, 2008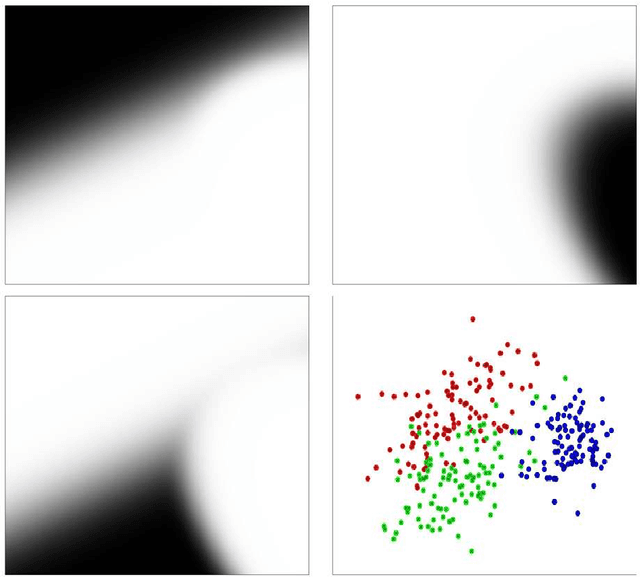
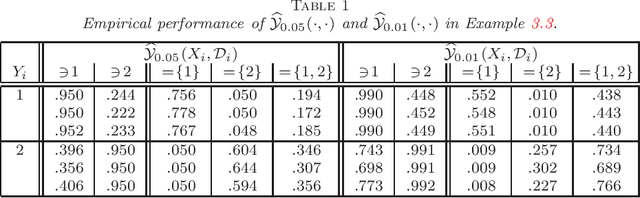
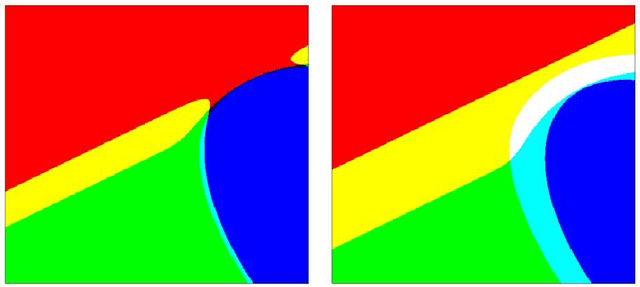
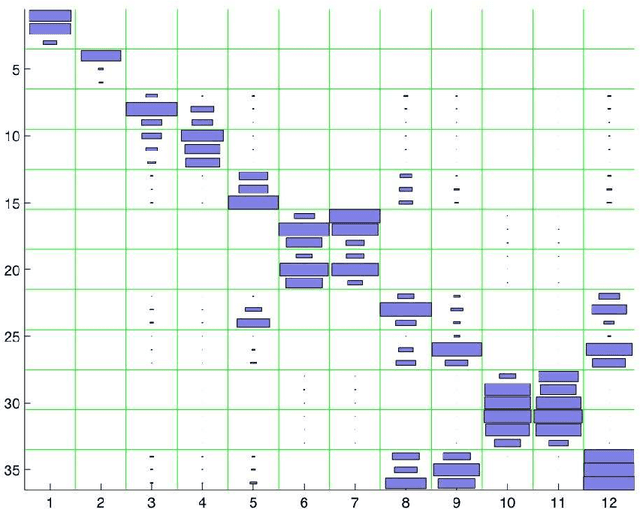
Let $(X,Y)$ be a random variable consisting of an observed feature vector $X\in \mathcal{X}$ and an unobserved class label $Y\in \{1,2,...,L\}$ with unknown joint distribution. In addition, let $\mathcal{D}$ be a training data set consisting of $n$ completely observed independent copies of $(X,Y)$. Usual classification procedures provide point predictors (classifiers) $\widehat{Y}(X,\mathcal{D})$ of $Y$ or estimate the conditional distribution of $Y$ given $X$. In order to quantify the certainty of classifying $X$ we propose to construct for each $\theta =1,2,...,L$ a p-value $\pi_{\theta}(X,\mathcal{D})$ for the null hypothesis that $Y=\theta$, treating $Y$ temporarily as a fixed parameter. In other words, the point predictor $\widehat{Y}(X,\mathcal{D})$ is replaced with a prediction region for $Y$ with a certain confidence. We argue that (i) this approach is advantageous over traditional approaches and (ii) any reasonable classifier can be modified to yield nonparametric p-values. We discuss issues such as optimality, single use and multiple use validity, as well as computational and graphical aspects.
* Published in at http://dx.doi.org/10.1214/08-EJS245 the Electronic Journal of Statistics (http://www.i-journals.org/ejs/) by the Institute of Mathematical Statistics (http://www.imstat.org)