 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Clustering using Hyperdimensional Computing
Dec 05, 2023This paper addresses the clustering of data in the hyperdimensional computing (HDC) domain. In prior work, an HDC-based clustering framework, referred to as HDCluster, has been proposed. However, the performance of the existing HDCluster is not robust. The performance of HDCluster is degraded as the hypervectors for the clusters are chosen at random during the initialization step. To overcome this bottleneck, we assign the initial cluster hypervectors by exploring the similarity of the encoded data, referred to as \textit{query} hypervectors. Intra-cluster hypervectors have a higher similarity than inter-cluster hypervectors. Harnessing the similarity results among query hypervectors, this paper proposes four HDC-based clustering algorithms: similarity-based k-means, equal bin-width histogram, equal bin-height histogram, and similarity-based affinity propagation. Experimental results illustrate that: (i) Compared to the existing HDCluster, our proposed HDC-based clustering algorithms can achieve better accuracy, more robust performance, fewer iterations, and less execution time. Similarity-based affinity propagation outperforms the other three HDC-based clustering algorithms on eight datasets by 2~38% in clustering accuracy. (ii) Even for one-pass clustering, i.e., without any iterative update of the cluster hypervectors, our proposed algorithms can provide more robust clustering accuracy than HDCluster. (iii) Over eight datasets, five out of eight can achieve higher or comparable accuracy when projected onto the hyperdimensional space. Traditional clustering is more desirable than HDC when the number of clusters, $k$, is large.
Classification using Hyperdimensional Computing: A Review
Apr 19, 2020
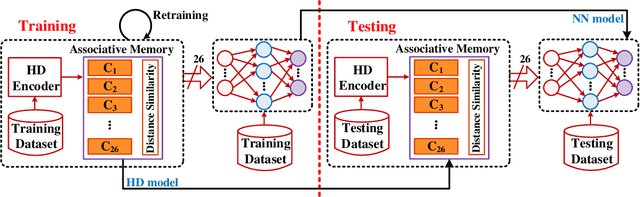
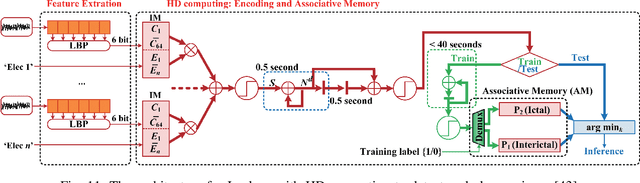
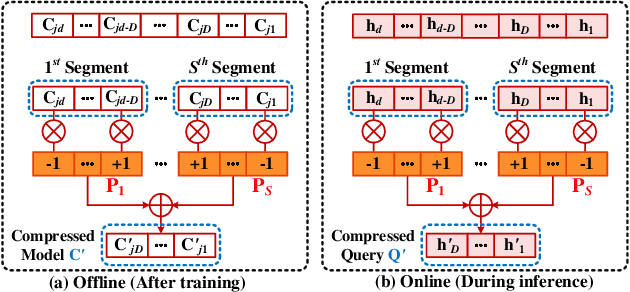
Hyperdimensional (HD) computing is built upon its unique data type referred to as hypervectors. The dimension of these hypervectors is typically in the range of tens of thousands. Proposed to solve cognitive tasks, HD computing aims at calculating similarity among its data. Data transformation is realized by three operations, including addition, multiplication and permutation. Its ultra-wide data representation introduces redundancy against noise. Since information is evenly distributed over every bit of the hypervectors, HD computing is inherently robust. Additionally, due to the nature of those three operations, HD computing leads to fast learning ability, high energy efficiency and acceptable accuracy in learning and classification tasks. This paper introduces the background of HD computing, and reviews the data representation, data transformation, and similarity measurement. The orthogonality in high dimensions presents opportunities for flexible computing. To balance the tradeoff between accuracy and efficiency, strategies include but are not limited to encoding, retraining, binarization and hardware acceleration. Evaluations indicate that HD computing shows great potential in addressing problems using data in the form of letters, signals and images. HD computing especially shows significant promise to replace machine learning algorithms as a light-weight classifier in the field of internet of things (IoTs).