 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow certain are your uncertainties?
Mar 01, 2022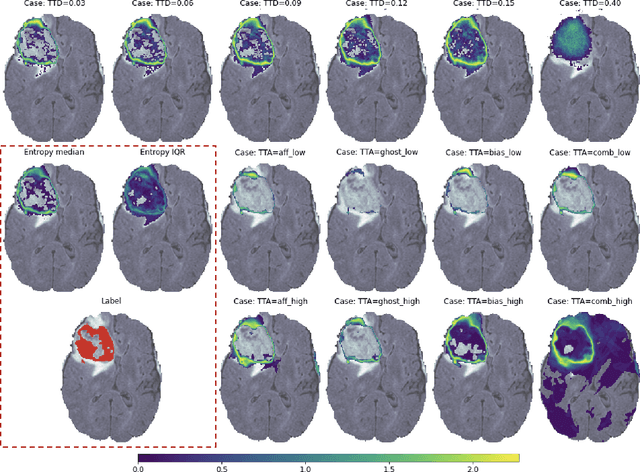

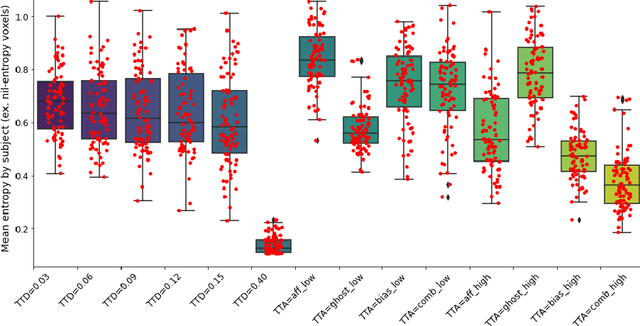
Having a measure of uncertainty in the output of a deep learning method is useful in several ways, such as in assisting with interpretation of the outputs, helping build confidence with end users, and for improving the training and performance of the networks. Therefore, several different methods have been proposed to capture various types of uncertainty, including epistemic (relating to the model used) and aleatoric (relating to the data) sources, with the most commonly used methods for estimating these being test-time dropout for epistemic uncertainty and test-time augmentation for aleatoric uncertainty. However, these methods are parameterised (e.g. amount of dropout or type and level of augmentation) and so there is a whole range of possible uncertainties that could be calculated, even with a fixed network and dataset. This work investigates the stability of these uncertainty measurements, in terms of both magnitude and spatial pattern. In experiments using the well characterised BraTS challenge, we demonstrate substantial variability in the magnitude and spatial pattern of these uncertainties, and discuss the implications for interpretability, repeatability and confidence in results.