 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Downlink Beamforming with Outage Constraints under Imperfect CSI using Model-Driven Deep Learning
Jan 07, 2026We consider energy-efficient multi-user hybrid downlink beamforming (BF) and power allocation under imperfect channel state information (CSI) and probabilistic outage constraints. In this domain, classical optimization methods resort to computationally costly conic optimization problems. Meanwhile, generic deep network (DN) architectures lack interpretability and require large training data sets to generalize well. In this paper, we therefore propose a lightweight model-aided deep learning architecture based on a greedy selection algorithm for analog beam codewords. The architecture relies on an instance-adaptive augmentation of the signal model to estimate the impact of the CSI error. To learn the DN parameters, we derive a novel and efficient implicit representation of the nested constrained BF problem and prove sufficient conditions for the existence of the corresponding gradient. In the loss function, we utilize an annealing-based approximation of the outage compared to conventional quantile-based loss terms. This approximation adaptively anneals towards the exact probabilistic constraint depending on the current level of quality of service (QoS) violation. Simulations validate that the proposed DN can achieve the nominal outage level under CSI error due to channel estimation and channel compression, while allocating less power than benchmarks. Thereby, a single trained model generalizes to different numbers of users, QoS requirements and levels of CSI quality. We further show that the adaptive annealing-based loss function can accelerate the training and yield a better power-outage trade-off.
Adaptive Anomaly Detection in Network Flows with Low-Rank Tensor Decompositions and Deep Unrolling
Sep 17, 2024
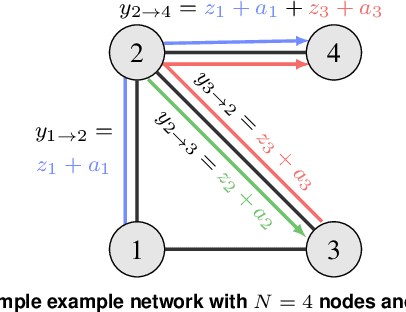
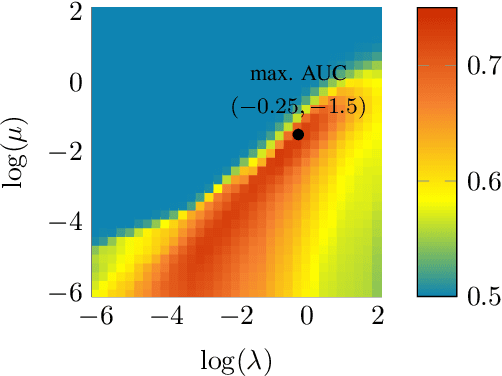
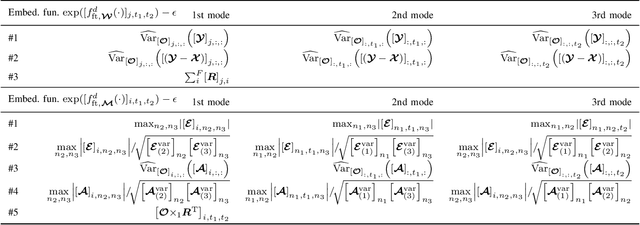
Anomaly detection (AD) is increasingly recognized as a key component for ensuring the resilience of future communication systems. While deep learning has shown state-of-the-art AD performance, its application in critical systems is hindered by concerns regarding training data efficiency, domain adaptation and interpretability. This work considers AD in network flows using incomplete measurements, leveraging a robust tensor decomposition approach and deep unrolling techniques to address these challenges. We first propose a novel block-successive convex approximation algorithm based on a regularized model-fitting objective where the normal flows are modeled as low-rank tensors and anomalies as sparse. An augmentation of the objective is introduced to decrease the computational cost. We apply deep unrolling to derive a novel deep network architecture based on our proposed algorithm, treating the regularization parameters as learnable weights. Inspired by Bayesian approaches, we extend the model architecture to perform online adaptation to per-flow and per-time-step statistics, improving AD performance while maintaining a low parameter count and preserving the problem's permutation equivariances. To optimize the deep network weights for detection performance, we employ a homotopy optimization approach based on an efficient approximation of the area under the receiver operating characteristic curve. Extensive experiments on synthetic and real-world data demonstrate that our proposed deep network architecture exhibits a high training data efficiency, outperforms reference methods, and adapts seamlessly to varying network topologies.
Coordinated Sum-Rate Maximization in Multicell MU-MIMO with Deep Unrolling
Feb 21, 2022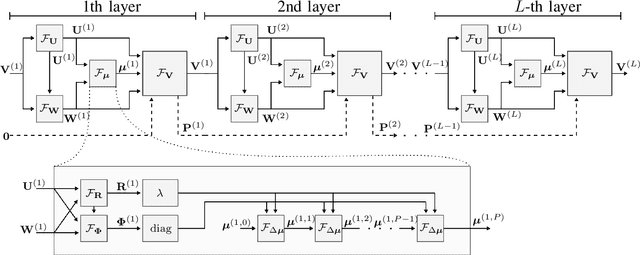
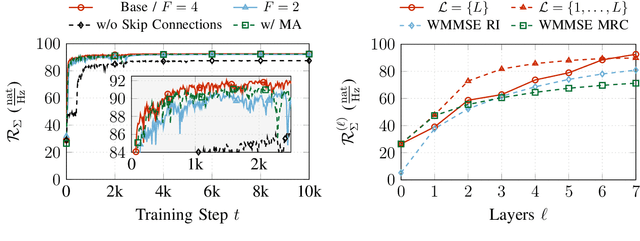
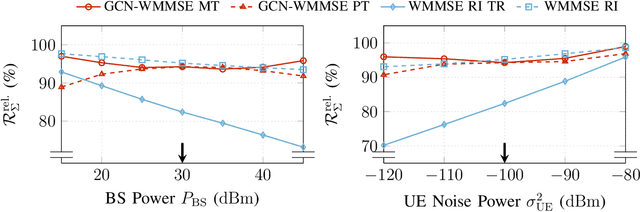
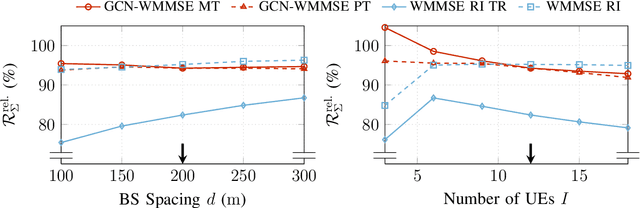
Coordinated weighted sum-rate maximization in multicell MIMO networks with intra- and intercell interference and local channel state at the base stations is recognized as an important yet difficult problem. A classical, locally optimal solution is obtained by the weighted minimum mean squared error (WMMSE) algorithm which facilitates a distributed implementation in multicell networks. However, it often suffers from slow convergence and therefore large communication overhead. To obtain more practical solutions, the unrolling/unfolding of traditional iterative algorithms gained significant attention. In this work, we demonstrate a complete unfolding of the WMMSE algorithm for transceiver design in multicell MU-MIMO interference channels with local channel state information. The resulting architecture termed GCN-WMMSE applies ideas from graph signal processing and is agnostic to different wireless network topologies, while exhibiting a low number of trainable parameters and high efficiency w.r.t. training data. It significantly reduces the number of required iterations while achieving performance similar to the WMMSE algorithm, alleviating the overhead in a distributed deployment. Additionally, we review previous architectures based on unrolling the WMMSE algorithm and compare them to GCN-WMMSE in their specific applicable domains.