 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Capabilities and Limitations of Machine Learning for Identifying Bias in English Language Data with Information and Heritage Professionals
Apr 01, 2025Despite numerous efforts to mitigate their biases, ML systems continue to harm already-marginalized people. While predominant ML approaches assume bias can be removed and fair models can be created, we show that these are not always possible, nor desirable, goals. We reframe the problem of ML bias by creating models to identify biased language, drawing attention to a dataset's biases rather than trying to remove them. Then, through a workshop, we evaluated the models for a specific use case: workflows of information and heritage professionals. Our findings demonstrate the limitations of ML for identifying bias due to its contextual nature, the way in which approaches to mitigating it can simultaneously privilege and oppress different communities, and its inevitability. We demonstrate the need to expand ML approaches to bias and fairness, providing a mixed-methods approach to investigating the feasibility of removing bias or achieving fairness in a given ML use case.
Situated Data, Situated Systems: A Methodology to Engage with Power Relations in Natural Language Processing Research
Nov 11, 2020
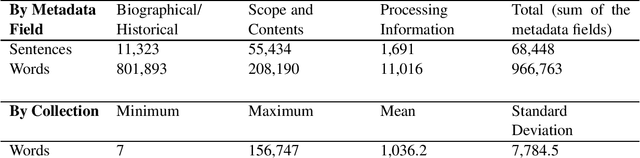
We propose a bias-aware methodology to engage with power relations in natural language processing (NLP) research. NLP research rarely engages with bias in social contexts, limiting its ability to mitigate bias. While researchers have recommended actions, technical methods, and documentation practices, no methodology exists to integrate critical reflections on bias with technical NLP methods. In this paper, after an extensive and interdisciplinary literature review, we contribute a bias-aware methodology for NLP research. We also contribute a definition of biased text, a discussion of the implications of biased NLP systems, and a case study demonstrating how we are executing the bias-aware methodology in research on archival metadata descriptions.