 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierLight-YOLO: A Hierarchical and Lightweight Object Detection Network for UAV Photography
Sep 26, 2025



The real-time detection of small objects in complex scenes, such as the unmanned aerial vehicle (UAV) photography captured by drones, has dual challenges of detecting small targets (<32 pixels) and maintaining real-time efficiency on resource-constrained platforms. While YOLO-series detectors have achieved remarkable success in real-time large object detection, they suffer from significantly higher false negative rates for drone-based detection where small objects dominate, compared to large object scenarios. This paper proposes HierLight-YOLO, a hierarchical feature fusion and lightweight model that enhances the real-time detection of small objects, based on the YOLOv8 architecture. We propose the Hierarchical Extended Path Aggregation Network (HEPAN), a multi-scale feature fusion method through hierarchical cross-level connections, enhancing the small object detection accuracy. HierLight-YOLO includes two innovative lightweight modules: Inverted Residual Depthwise Convolution Block (IRDCB) and Lightweight Downsample (LDown) module, which significantly reduce the model's parameters and computational complexity without sacrificing detection capabilities. Small object detection head is designed to further enhance spatial resolution and feature fusion to tackle the tiny object (4 pixels) detection. Comparison experiments and ablation studies on the VisDrone2019 benchmark demonstrate state-of-the-art performance of HierLight-YOLO.
SL-YOLO: A Stronger and Lighter Drone Target Detection Model
Nov 18, 2024


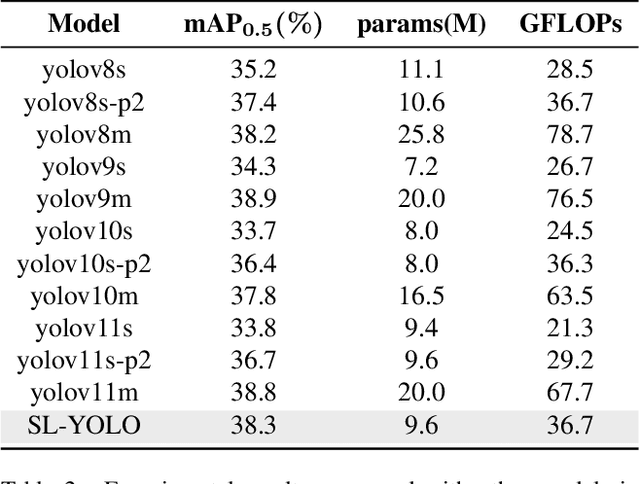
Detecting small objects in complex scenes, such as those captured by drones, is a daunting challenge due to the difficulty in capturing the complex features of small targets. While the YOLO family has achieved great success in large target detection, its performance is less than satisfactory when faced with small targets. Because of this, this paper proposes a revolutionary model SL-YOLO (Stronger and Lighter YOLO) that aims to break the bottleneck of small target detection. We propose the Hierarchical Extended Path Aggregation Network (HEPAN), a pioneering cross-scale feature fusion method that can ensure unparalleled detection accuracy even in the most challenging environments. At the same time, without sacrificing detection capabilities, we design the C2fDCB lightweight module and add the SCDown downsampling module to greatly reduce the model's parameters and computational complexity. Our experimental results on the VisDrone2019 dataset reveal a significant improvement in performance, with mAP@0.5 jumping from 43.0% to 46.9% and mAP@0.5:0.95 increasing from 26.0% to 28.9%. At the same time, the model parameters are reduced from 11.1M to 9.6M, and the FPS can reach 132, making it an ideal solution for real-time small object detection in resource-constrained environments.
ElasticLaneNet: A Geometry-Flexible Approach for Lane Detection
Dec 16, 2023The task of lane detection involves identifying the boundaries of driving areas. Recognizing lanes with complex and variable geometric structures remains a challenge. In this paper, we introduce a new lane detection framework named ElasticLaneNet (Elastic-interaction-energy guided Lane detection Network). A novel and flexible way of representing lanes, namely, implicit representation is proposed. The training strategy considers predicted lanes as moving curves that being attracted to the ground truth guided by an elastic interaction energy based loss function (EIE loss). An auxiliary feature refinement (AFR) module is designed to gather information from different layers. The method performs well in complex lane scenarios, including those with large curvature, weak geometric features at intersections, complicated cross lanes, Y-shapes lanes, dense lanes, etc. We apply our approach on three datasets: SDLane, CULane, and TuSimple. The results demonstrate the exceptional performance of our method, with the state-of-the-art results on the structure-diversity dataset SDLane, achieving F1-score of 89.51, Recall rate of 87.50, and Precision of 91.61.
Elastic Interaction Energy Loss for Traffic Image Segmentation
Oct 02, 2023Segmentation is a pixel-level classification of images. The accuracy and fast inference speed of image segmentation are crucial for autonomous driving safety. Fine and complex geometric objects are the most difficult but important recognition targets in traffic scene, such as pedestrians, traffic signs and lanes. In this paper, a simple and efficient geometry-sensitive energy-based loss function is proposed to Convolutional Neural Network (CNN) for multi-class segmentation on real-time traffic scene understanding. To be specific, the elastic interaction energy (EIE) between two boundaries will drive the prediction moving toward the ground truth until completely overlap. The EIE loss function is incorporated into CNN to enhance accuracy on fine-scale structure segmentation. In particular, small or irregularly shaped objects can be identified more accurately, and discontinuity issues on slender objects can be improved. Our approach can be applied to different segmentation-based problems, such as urban scene segmentation and lane detection. We quantitatively and qualitatively analyze our method on three traffic datasets, including urban scene data Cityscapes, lane data TuSimple and CULane. The results show that our approach consistently improves performance, especially when using real-time, lightweight networks as the backbones, which is more suitable for autonomous driving.
Energy stable neural network for gradient flow equations
Sep 17, 2023



In this paper, we propose an energy stable network (EStable-Net) for solving gradient flow equations. The solution update scheme in our neural network EStable-Net is inspired by a proposed auxiliary variable based equivalent form of the gradient flow equation. EStable-Net enables decreasing of a discrete energy along the neural network, which is consistent with the property in the evolution process of the gradient flow equation. The architecture of the neural network EStable-Net consists of a few energy decay blocks, and the output of each block can be interpreted as an intermediate state of the evolution process of the gradient flow equation. This design provides a stable, efficient and interpretable network structure. Numerical experimental results demonstrate that our network is able to generate high accuracy and stable predictions.
Large Transformers are Better EEG Learners
Aug 20, 2023



Pre-trained large transformer models have achieved remarkable performance in the fields of natural language processing and computer vision. Since the magnitude of available labeled electroencephalogram (EEG) data is much lower than that of text and image data, it is difficult for transformer models pre-trained from EEG to be developed as large as GPT-4 100T to fully unleash the potential of this architecture. In this paper, we show that transformers pre-trained from images as well as text can be directly fine-tuned for EEG-based prediction tasks. We design AdaCE, plug-and-play Adapters for Converting EEG data into image as well as text forms, to fine-tune pre-trained vision and language transformers. The proposed AdaCE module is highly effective for fine-tuning pre-trained transformers while achieving state-of-the-art performance on diverse EEG-based prediction tasks. For example, AdaCE on the pre-trained Swin-Transformer achieves 99.6%, an absolute improvement of 9.2%, on the EEG-decoding task of human activity recognition (UCI HAR). Furthermore, we empirically show that applying the proposed AdaCE to fine-tune larger pre-trained models can achieve better performance on EEG-based predicting tasks, indicating the potential of our adapters for even larger transformers. The plug-and-play AdaCE module can be applied to fine-tuning most of the popular pre-trained transformers on many other time-series data with multiple channels, not limited to EEG data and the models we use. Our code will be available at https://github.com/wangbxj1234/AdaCE.
Feature Flow Regularization: Improving Structured Sparsity in Deep Neural Networks
Jun 05, 2021
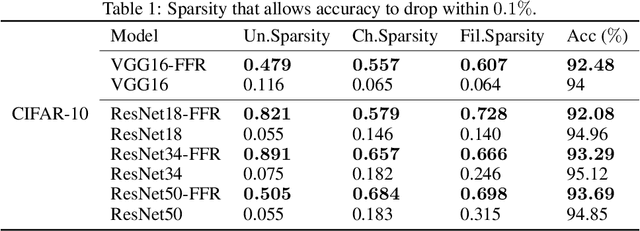
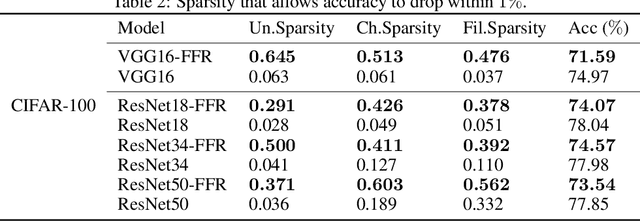
Pruning is a model compression method that removes redundant parameters in deep neural networks (DNNs) while maintaining accuracy. Most available filter pruning methods require complex treatments such as iterative pruning, features statistics/ranking, or additional optimization designs in the training process. In this paper, we propose a simple and effective regularization strategy from a new perspective of evolution of features, which we call feature flow regularization (FFR), for improving structured sparsity and filter pruning in DNNs. Specifically, FFR imposes controls on the gradient and curvature of feature flow along the neural network, which implicitly increases the sparsity of the parameters. The principle behind FFR is that coherent and smooth evolution of features will lead to an efficient network that avoids redundant parameters. The high structured sparsity obtained from FFR enables us to prune filters effectively. Experiments with VGGNets, ResNets on CIFAR-10/100, and Tiny ImageNet datasets demonstrate that FFR can significantly improve both unstructured and structured sparsity. Our pruning results in terms of reduction of parameters and FLOPs are comparable to or even better than those of state-of-the-art pruning methods.
An Elastic Interaction-Based Loss Function for Medical Image Segmentation
Jul 06, 2020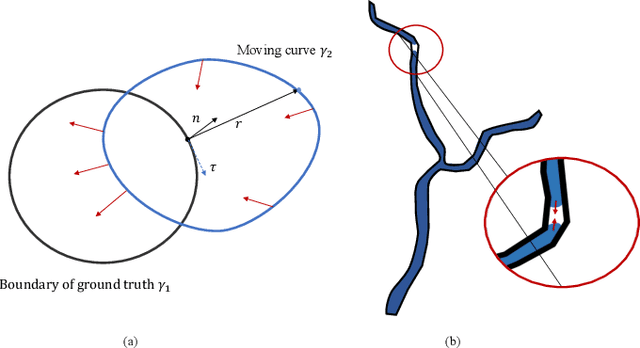
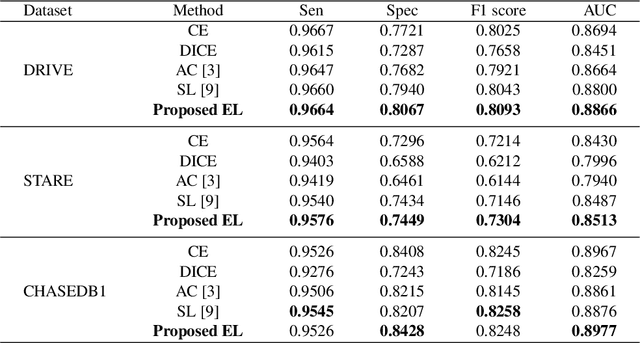
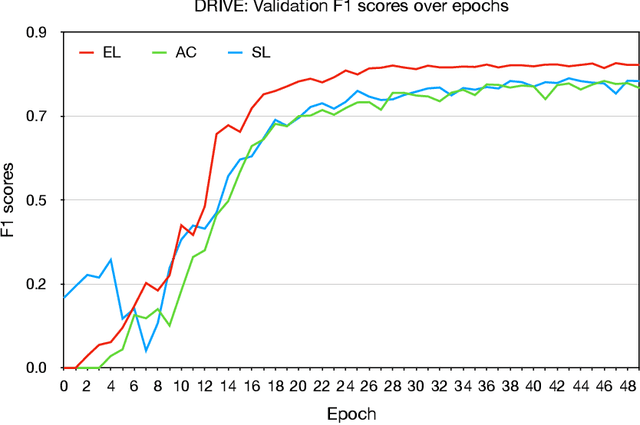
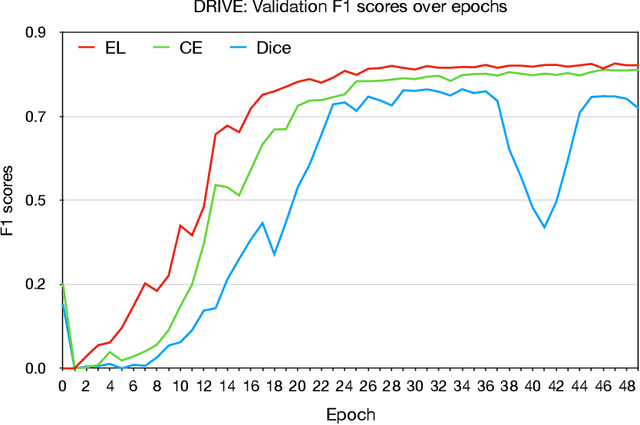
Deep learning techniques have shown their success in medical image segmentation since they are easy to manipulate and robust to various types of datasets. The commonly used loss functions in the deep segmentation task are pixel-wise loss functions. This results in a bottleneck for these models to achieve high precision for complicated structures in biomedical images. For example, the predicted small blood vessels in retinal images are often disconnected or even missed under the supervision of the pixel-wise losses. This paper addresses this problem by introducing a long-range elastic interaction-based training strategy. In this strategy, convolutional neural network (CNN) learns the target region under the guidance of the elastic interaction energy between the boundary of the predicted region and that of the actual object. Under the supervision of the proposed loss, the boundary of the predicted region is attracted strongly by the object boundary and tends to stay connected. Experimental results show that our method is able to achieve considerable improvements compared to commonly used pixel-wise loss functions (cross entropy and dice Loss) and other recent loss functions on three retinal vessel segmentation datasets, DRIVE, STARE and CHASEDB1.